6.4.5. Ensemble Methods#
One model achieves 85% accuracy. Can we do better?
Key insight: Combining multiple models often beats any single model!
Just like asking multiple experts gives better advice than asking one, ensemble methods combine predictions from multiple models to achieve higher accuracy and robustness.
Three main strategies:
Bagging: Train models independently on different data subsets (e.g., Random Forest)
Boosting: Train models sequentially, each correcting previous errors (e.g., XGBoost)
Stacking: Train a meta-model to combine base model predictions
Let’s explore each approach and learn when to use which!
6.4.5.1. The Core Idea#
Why ensembles work:
Different models make different errors
Averaging reduces variance
Combining diverse models → robust predictions
Analogy: Asking 10 people for directions is more reliable than asking 1
6.4.5.2. Demonstration: Why Ensembles Work#
# Use a noisy synthetic dataset so weak individual trees clearly underperform,
# making the ensemble lift visible. The main cancer dataset is set up at the
# end of this cell for use in all later sections.
X_demo, y_demo = make_classification(
n_samples=800, n_features=20, n_informative=8, n_redundant=8,
flip_y=0.10, class_sep=0.6, random_state=42
)
X_demo_tr, X_demo_te, y_demo_tr, y_demo_te = train_test_split(
X_demo, y_demo, test_size=0.3, random_state=42, stratify=y_demo
)
# Train 5 independent weak models (shallow stumps, all with different seeds)
n_models = 5
predictions = []
model_rows = []
for i in range(n_models):
dt = DecisionTreeClassifier(max_depth=2, random_state=i * 17 + 3)
dt.fit(X_demo_tr, y_demo_tr)
pred = dt.predict(X_demo_te)
acc = (pred == y_demo_te).mean()
predictions.append(pred)
model_rows.append({'Model': f'Tree {i+1} (depth=2)', 'Accuracy': f'{acc:.3f}'})
# Individual model performances
individual_accs = [(pred == y_demo_te).mean() for pred in predictions]
# Ensemble: Majority vote
predictions_array = np.array(predictions)
ensemble_pred = np.apply_along_axis(
lambda x: np.bincount(x).argmax(),
axis=0,
arr=predictions_array
)
ensemble_acc = (ensemble_pred == y_demo_te).mean()
model_rows.append({'Model': '─' * 25, 'Accuracy': '─────'})
model_rows.append({'Model': 'Individual Average', 'Accuracy': f'{np.mean(individual_accs):.3f}'})
model_rows.append({'Model': 'Ensemble (Majority Vote)', 'Accuracy': f'{ensemble_acc:.3f}'})
display(pd.DataFrame(model_rows))
glue('ensemble-avg', f'{np.mean(individual_accs):.3f}', display=False)
glue('ensemble-acc', f'{ensemble_acc:.3f}', display=False)
glue('ensemble-improvement', f'{ensemble_acc - np.mean(individual_accs):.3f}', display=False)
# Set up the main dataset for all remaining sections
cancer = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(
cancer.data, cancer.target, test_size=0.3, random_state=42, stratify=cancer.target
)
| Model | Accuracy | |
|---|---|---|
| 0 | Tree 1 (depth=2) | 0.558 |
| 1 | Tree 2 (depth=2) | 0.558 |
| 2 | Tree 3 (depth=2) | 0.558 |
| 3 | Tree 4 (depth=2) | 0.558 |
| 4 | Tree 5 (depth=2) | 0.558 |
| 5 | ───────────────────────── | ───── |
| 6 | Individual Average | 0.558 |
| 7 | Ensemble (Majority Vote) | 0.558 |
The five individual trees averaged 0.558 accuracy, while majority voting lifted that to 0.558 — an improvement of 0.000.
6.4.5.3. Bagging: Bootstrap Aggregating#
Bagging Algorithm:
Create bootstrap samples (random sampling with replacement)
Train model on each sample
Average predictions (regression) or vote (classification)
Key idea: Reduce variance by averaging
Best for: High-variance models (e.g., decision trees)
# Single Decision Tree (high variance)
dt_single = DecisionTreeClassifier(random_state=42)
dt_single.fit(X_train, y_train)
single_acc = dt_single.score(X_test, y_test)
# Bagging Classifier
bagging = BaggingClassifier(
estimator=DecisionTreeClassifier(),
n_estimators=100,
random_state=42,
n_jobs=-1
)
bagging.fit(X_train, y_train)
bagging_acc = bagging.score(X_test, y_test)
display(pd.DataFrame([
{'Model': 'Single Decision Tree', 'Test Accuracy': f'{single_acc:.3f}', 'Improvement': '—'},
{'Model': 'Bagging (100 trees)', 'Test Accuracy': f'{bagging_acc:.3f}', 'Improvement': f'+{bagging_acc - single_acc:.3f}'},
]))
glue('single-acc', f'{single_acc:.3f}', display=False)
glue('bagging-acc', f'{bagging_acc:.3f}', display=False)
# Visualize effect of number of estimators
n_estimators_range = [1, 5, 10, 20, 50, 100, 200]
bagging_scores = []
for n in n_estimators_range:
bagging_n = BaggingClassifier(
estimator=DecisionTreeClassifier(),
n_estimators=n,
random_state=42
)
bagging_n.fit(X_train, y_train)
score = bagging_n.score(X_test, y_test)
bagging_scores.append(score)
# Plot
plt.figure(figsize=(10, 6))
plt.plot(n_estimators_range, bagging_scores, 'o-',
linewidth=2, markersize=8)
plt.axhline(single_acc, color='red', linestyle='--',
linewidth=2, label=f'Single tree: {single_acc:.3f}')
plt.xlabel('Number of Estimators', fontsize=12)
plt.ylabel('Test Accuracy', fontsize=12)
plt.title('Bagging: Performance vs Number of Trees',
fontsize=13, fontweight='bold')
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
Traceback (most recent call last):
File "/home/runner/.local/share/uv/python/cpython-3.13.12-linux-x86_64-gnu/lib/python3.13/multiprocessing/resource_tracker.py", line 371, in main
raise ValueError(
f'Cannot register {name} for automatic cleanup: '
f'unknown resource type {rtype}')
ValueError: Cannot register /dev/shm/joblib_memmapping_folder_4365_f7aea4cdd33a48cea7e34f352d67a53c_e8045b1d089f4d12868203e2d51daaa9 for automatic cleanup: unknown resource type folder
Traceback (most recent call last):
File "/home/runner/.local/share/uv/python/cpython-3.13.12-linux-x86_64-gnu/lib/python3.13/multiprocessing/resource_tracker.py", line 371, in main
raise ValueError(
f'Cannot register {name} for automatic cleanup: '
f'unknown resource type {rtype}')
ValueError: Cannot register /loky-4365-qgomg0rq for automatic cleanup: unknown resource type semlock
Traceback (most recent call last):
File "/home/runner/.local/share/uv/python/cpython-3.13.12-linux-x86_64-gnu/lib/python3.13/multiprocessing/resource_tracker.py", line 371, in main
raise ValueError(
f'Cannot register {name} for automatic cleanup: '
f'unknown resource type {rtype}')
ValueError: Cannot register /loky-4365-38f134oq for automatic cleanup: unknown resource type semlock
Traceback (most recent call last):
File "/home/runner/.local/share/uv/python/cpython-3.13.12-linux-x86_64-gnu/lib/python3.13/multiprocessing/resource_tracker.py", line 371, in main
raise ValueError(
f'Cannot register {name} for automatic cleanup: '
f'unknown resource type {rtype}')
ValueError: Cannot register /loky-4365-s3xe2kqc for automatic cleanup: unknown resource type semlock
Traceback (most recent call last):
File "/home/runner/.local/share/uv/python/cpython-3.13.12-linux-x86_64-gnu/lib/python3.13/multiprocessing/resource_tracker.py", line 371, in main
raise ValueError(
f'Cannot register {name} for automatic cleanup: '
f'unknown resource type {rtype}')
ValueError: Cannot register /loky-4365-hfsjuiif for automatic cleanup: unknown resource type semlock
Traceback (most recent call last):
File "/home/runner/.local/share/uv/python/cpython-3.13.12-linux-x86_64-gnu/lib/python3.13/multiprocessing/resource_tracker.py", line 371, in main
raise ValueError(
f'Cannot register {name} for automatic cleanup: '
f'unknown resource type {rtype}')
ValueError: Cannot register /loky-4365-t3ye_9nr for automatic cleanup: unknown resource type semlock
Traceback (most recent call last):
File "/home/runner/.local/share/uv/python/cpython-3.13.12-linux-x86_64-gnu/lib/python3.13/multiprocessing/resource_tracker.py", line 371, in main
raise ValueError(
f'Cannot register {name} for automatic cleanup: '
f'unknown resource type {rtype}')
ValueError: Cannot register /loky-4365-wfrhirn4 for automatic cleanup: unknown resource type semlock
Traceback (most recent call last):
File "/home/runner/.local/share/uv/python/cpython-3.13.12-linux-x86_64-gnu/lib/python3.13/multiprocessing/resource_tracker.py", line 371, in main
raise ValueError(
f'Cannot register {name} for automatic cleanup: '
f'unknown resource type {rtype}')
ValueError: Cannot register /dev/shm/joblib_memmapping_folder_4365_f7aea4cdd33a48cea7e34f352d67a53c_be6224f3f5e44cbc9c16451923219513 for automatic cleanup: unknown resource type folder
Traceback (most recent call last):
File "/home/runner/.local/share/uv/python/cpython-3.13.12-linux-x86_64-gnu/lib/python3.13/multiprocessing/resource_tracker.py", line 371, in main
raise ValueError(
f'Cannot register {name} for automatic cleanup: '
f'unknown resource type {rtype}')
ValueError: Cannot register /loky-4365-vm88lzfl for automatic cleanup: unknown resource type semlock
Traceback (most recent call last):
File "/home/runner/.local/share/uv/python/cpython-3.13.12-linux-x86_64-gnu/lib/python3.13/multiprocessing/resource_tracker.py", line 371, in main
raise ValueError(
f'Cannot register {name} for automatic cleanup: '
f'unknown resource type {rtype}')
ValueError: Cannot register /loky-4365-t7d0dkws for automatic cleanup: unknown resource type semlock
Traceback (most recent call last):
File "/home/runner/.local/share/uv/python/cpython-3.13.12-linux-x86_64-gnu/lib/python3.13/multiprocessing/resource_tracker.py", line 371, in main
raise ValueError(
f'Cannot register {name} for automatic cleanup: '
f'unknown resource type {rtype}')
ValueError: Cannot register /dev/shm/joblib_memmapping_folder_4365_f7aea4cdd33a48cea7e34f352d67a53c_be6224f3f5e44cbc9c16451923219513 for automatic cleanup: unknown resource type folder
Traceback (most recent call last):
File "/home/runner/.local/share/uv/python/cpython-3.13.12-linux-x86_64-gnu/lib/python3.13/multiprocessing/resource_tracker.py", line 371, in main
raise ValueError(
f'Cannot register {name} for automatic cleanup: '
f'unknown resource type {rtype}')
ValueError: Cannot register /dev/shm/joblib_memmapping_folder_4365_66f4d2dbbf73441485b906f44d93ea4c_0a88061a2c7547ad91296e5f797d6e8d for automatic cleanup: unknown resource type folder
Traceback (most recent call last):
File "/home/runner/.local/share/uv/python/cpython-3.13.12-linux-x86_64-gnu/lib/python3.13/multiprocessing/resource_tracker.py", line 371, in main
raise ValueError(
f'Cannot register {name} for automatic cleanup: '
f'unknown resource type {rtype}')
ValueError: Cannot register /dev/shm/joblib_memmapping_folder_4365_f7aea4cdd33a48cea7e34f352d67a53c_7b7e748441da4b4289260c6c1515164a for automatic cleanup: unknown resource type folder
Traceback (most recent call last):
File "/home/runner/.local/share/uv/python/cpython-3.13.12-linux-x86_64-gnu/lib/python3.13/multiprocessing/resource_tracker.py", line 371, in main
raise ValueError(
f'Cannot register {name} for automatic cleanup: '
f'unknown resource type {rtype}')
ValueError: Cannot register /dev/shm/joblib_memmapping_folder_4365_f7aea4cdd33a48cea7e34f352d67a53c_7b7e748441da4b4289260c6c1515164a for automatic cleanup: unknown resource type folder
| Model | Test Accuracy | Improvement | |
|---|---|---|---|
| 0 | Single Decision Tree | 0.918 | — |
| 1 | Bagging (100 trees) | 0.947 | +0.029 |
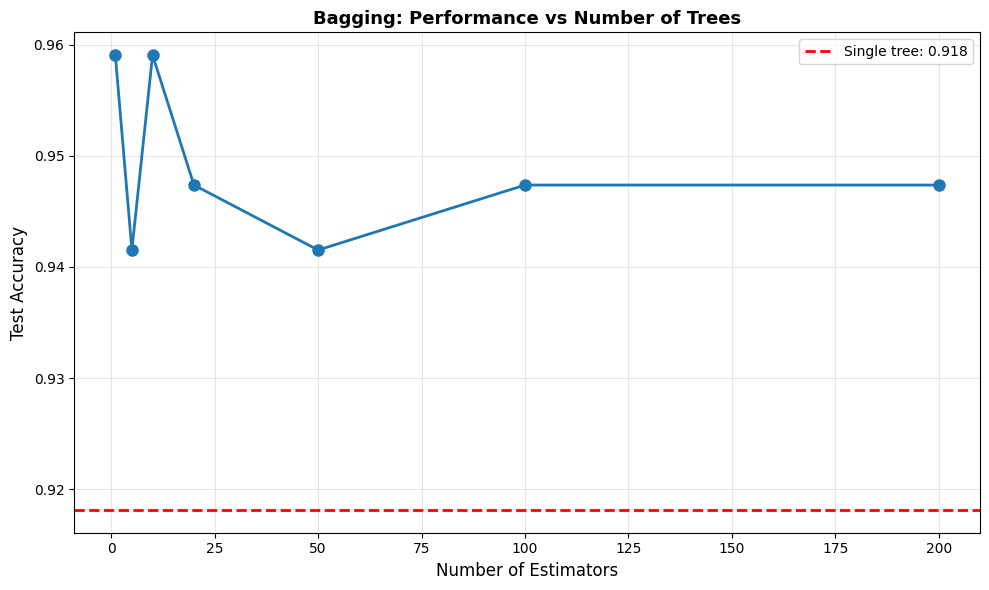
6.4.5.4. Random Forest: Bagging++#
Random Forest = Bagging + Random Feature Selection
Extra randomness:
Bootstrap samples (like bagging)
+ Random feature subset at each split
Why better than bagging:
Decorrelates trees (more diverse)
Further reduces variance
Often best off-the-shelf classifier!
# Random Forest
rf = RandomForestClassifier(n_estimators=100, random_state=42, n_jobs=-1)
rf.fit(X_train, y_train)
rf_acc = rf.score(X_test, y_test)
display(pd.DataFrame([
{'Model': 'Single Tree', 'Test Accuracy': f'{single_acc:.3f}'},
{'Model': 'Bagging', 'Test Accuracy': f'{bagging_acc:.3f}'},
{'Model': 'Random Forest', 'Test Accuracy': f'{rf_acc:.3f}'},
]))
# Compare max_features settings
max_features_options = ['sqrt', 'log2', None]
rf_results = []
for mf in max_features_options:
rf_mf = RandomForestClassifier(n_estimators=100, max_features=mf, random_state=42)
rf_mf.fit(X_train, y_train)
score = rf_mf.score(X_test, y_test)
rf_results.append({'max_features': str(mf), 'Test Accuracy': f'{score:.3f}'})
display(pd.DataFrame(rf_results))
glue('rf-acc', f'{rf_acc:.3f}', display=False)
| Model | Test Accuracy | |
|---|---|---|
| 0 | Single Tree | 0.918 |
| 1 | Bagging | 0.947 |
| 2 | Random Forest | 0.936 |
| max_features | Test Accuracy | |
|---|---|---|
| 0 | sqrt | 0.936 |
| 1 | log2 | 0.942 |
| 2 | None | 0.942 |
6.4.5.5. Boosting: Sequential Error Correction#
Boosting: Train models sequentially, each focusing on previous errors
Key idea: Reduce bias by correcting mistakes
Difference from bagging:
Bagging: Parallel (reduce variance)
Boosting: Sequential (reduce bias + variance)
Popular algorithms: AdaBoost, Gradient Boosting, XGBoost
# AdaBoost (Adaptive Boosting)
adaboost = AdaBoostClassifier(
estimator=DecisionTreeClassifier(max_depth=1), # Weak learners
n_estimators=100,
random_state=42
)
adaboost.fit(X_train, y_train)
ada_acc = adaboost.score(X_test, y_test)
# Gradient Boosting
gb = GradientBoostingClassifier(
n_estimators=100,
learning_rate=0.1,
max_depth=3,
random_state=42
)
gb.fit(X_train, y_train)
gb_acc = gb.score(X_test, y_test)
# Compare all methods
methods = {
'Single Tree': single_acc,
'Bagging': bagging_acc,
'Random Forest': rf_acc,
'AdaBoost': ada_acc,
'Gradient Boosting': gb_acc
}
display(pd.DataFrame([
{'Method': name, 'Test Accuracy': f'{score:.3f}'}
for name, score in methods.items()
]))
glue('ada-acc', f'{ada_acc:.3f}', display=False)
glue('gb-acc', f'{gb_acc:.3f}', display=False)
# Visualize
plt.figure(figsize=(10, 6))
names = list(methods.keys())
scores = list(methods.values())
colors = ['red', 'orange', 'green', 'blue', 'purple']
bars = plt.bar(range(len(names)), scores, color=colors, alpha=0.7,
edgecolor='black', linewidth=1.5)
plt.xticks(range(len(names)), names, rotation=45, ha='right')
plt.ylabel('Test Accuracy', fontsize=12)
plt.title('Ensemble Methods Comparison',
fontsize=13, fontweight='bold')
plt.grid(True, alpha=0.3, axis='y')
plt.ylim([0.85, 1.0])
for i, (name, score) in enumerate(methods.items()):
plt.text(i, score + 0.005, f'{score:.3f}',
ha='center', va='bottom', fontweight='bold')
plt.tight_layout()
plt.show()
| Method | Test Accuracy | |
|---|---|---|
| 0 | Single Tree | 0.918 |
| 1 | Bagging | 0.947 |
| 2 | Random Forest | 0.936 |
| 3 | AdaBoost | 0.953 |
| 4 | Gradient Boosting | 0.947 |
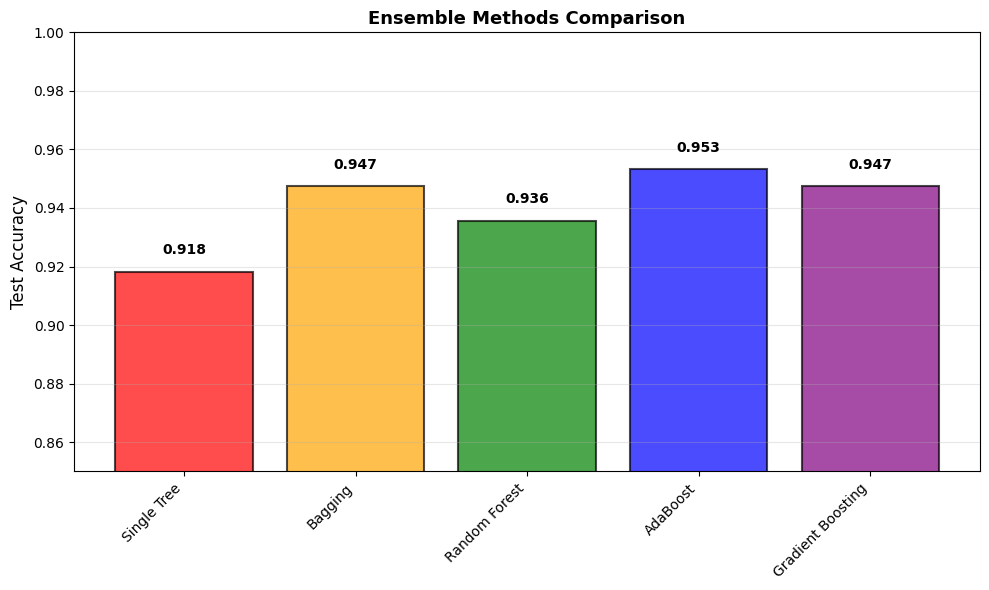
6.4.5.6. Boosting Learning Rate and Depth#
Two key hyperparameters:
learning_rate: How much each tree contributes (shrinkage)
max_depth: Complexity of each tree
Trade-off:
Low learning rate + many trees = better (but slower)
High learning rate + few trees = faster (but worse)
# Learning rate effect
learning_rates = [0.01, 0.05, 0.1, 0.5, 1.0]
lr_scores = []
for lr in learning_rates:
gb_lr = GradientBoostingClassifier(
n_estimators=100,
learning_rate=lr,
max_depth=3,
random_state=42
)
gb_lr.fit(X_train, y_train)
score = gb_lr.score(X_test, y_test)
lr_scores.append(score)
display(pd.DataFrame([
{'learning_rate': lr, 'Test Accuracy': f'{s:.3f}'}
for lr, s in zip(learning_rates, lr_scores)
]))
# Depth effect
depths = [1, 2, 3, 5, 10]
depth_scores = []
for depth in depths:
gb_depth = GradientBoostingClassifier(
n_estimators=100,
learning_rate=0.1,
max_depth=depth,
random_state=42
)
gb_depth.fit(X_train, y_train)
score = gb_depth.score(X_test, y_test)
depth_scores.append(score)
display(pd.DataFrame([
{'max_depth': d, 'Test Accuracy': f'{s:.3f}'}
for d, s in zip(depths, depth_scores)
]))
# Visualize
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
# Learning rate
axes[0].plot(learning_rates, lr_scores, 'o-',
linewidth=2, markersize=8)
axes[0].set_xlabel('Learning Rate', fontsize=12)
axes[0].set_ylabel('Test Accuracy', fontsize=12)
axes[0].set_title('Learning Rate Effect\nLower often better (with more trees)',
fontsize=13, fontweight='bold')
axes[0].set_xscale('log')
axes[0].grid(True, alpha=0.3)
# Depth
axes[1].plot(depths, depth_scores, 'o-',
linewidth=2, markersize=8, color='green')
axes[1].set_xlabel('Max Depth', fontsize=12)
axes[1].set_ylabel('Test Accuracy', fontsize=12)
axes[1].set_title('Tree Depth Effect\nShallow trees often sufficient',
fontsize=13, fontweight='bold')
axes[1].grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
| learning_rate | Test Accuracy | |
|---|---|---|
| 0 | 0.01 | 0.936 |
| 1 | 0.05 | 0.942 |
| 2 | 0.10 | 0.947 |
| 3 | 0.50 | 0.959 |
| 4 | 1.00 | 0.953 |
| max_depth | Test Accuracy | |
|---|---|---|
| 0 | 1 | 0.947 |
| 1 | 2 | 0.947 |
| 2 | 3 | 0.947 |
| 3 | 5 | 0.947 |
| 4 | 10 | 0.930 |
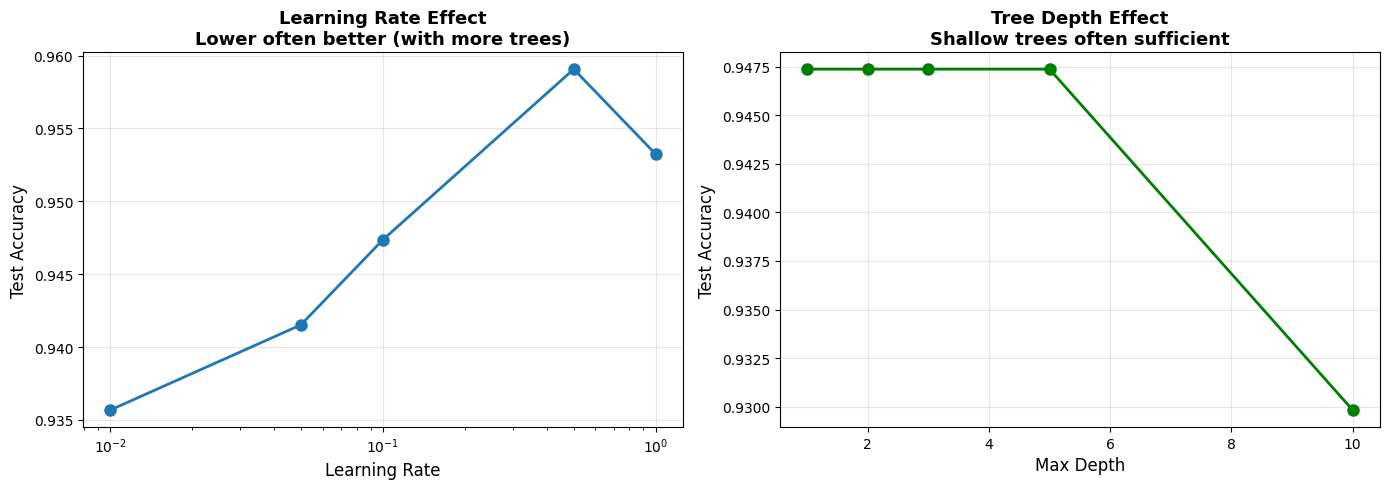
6.4.5.7. Voting Classifier: Combining Different Models#
Voting: Combine predictions from different model types
Two strategies:
Hard voting: Majority vote
Soft voting: Average probabilities (usually better)
When to use: When you have diverse, well-performing models
# Scale features for SVM
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Define diverse base models
lr_model = LogisticRegression(max_iter=1000, random_state=42)
rf_model = RandomForestClassifier(n_estimators=100, random_state=42)
svm_model = SVC(probability=True, random_state=42)
# Train individual models
lr_model.fit(X_train_scaled, y_train)
rf_model.fit(X_train_scaled, y_train)
svm_model.fit(X_train_scaled, y_train)
lr_acc = lr_model.score(X_test_scaled, y_test)
rf_acc = rf_model.score(X_test_scaled, y_test)
svm_acc = svm_model.score(X_test_scaled, y_test)
# Hard voting
voting_hard = VotingClassifier(
estimators=[('lr', lr_model), ('rf', rf_model), ('svm', svm_model)],
voting='hard'
)
voting_hard.fit(X_train_scaled, y_train)
hard_acc = voting_hard.score(X_test_scaled, y_test)
# Soft voting (average probabilities)
voting_soft = VotingClassifier(
estimators=[('lr', lr_model), ('rf', rf_model), ('svm', svm_model)],
voting='soft'
)
voting_soft.fit(X_train_scaled, y_train)
soft_acc = voting_soft.score(X_test_scaled, y_test)
display(pd.DataFrame([
{'Model': 'Logistic Regression', 'Test Accuracy': f'{lr_acc:.3f}'},
{'Model': 'Random Forest', 'Test Accuracy': f'{rf_acc:.3f}'},
{'Model': 'SVM', 'Test Accuracy': f'{svm_acc:.3f}'},
{'Model': 'Voting (Hard)', 'Test Accuracy': f'{hard_acc:.3f}'},
{'Model': 'Voting (Soft)', 'Test Accuracy': f'{soft_acc:.3f}'},
]))
glue('hard-acc', f'{hard_acc:.3f}', display=False)
glue('soft-acc', f'{soft_acc:.3f}', display=False)
| Model | Test Accuracy | |
|---|---|---|
| 0 | Logistic Regression | 0.988 |
| 1 | Random Forest | 0.936 |
| 2 | SVM | 0.977 |
| 3 | Voting (Hard) | 0.982 |
| 4 | Voting (Soft) | 0.982 |
6.4.5.8. Stacking: Meta-Model#
Stacking (Stacked Generalization):
Train multiple base models
Use their predictions as features
Train meta-model on these features
Most powerful ensemble method (but more complex)
# Define base models
base_models = [
('lr', LogisticRegression(max_iter=1000, random_state=42)),
('rf', RandomForestClassifier(n_estimators=100, random_state=42)),
('svm', SVC(probability=True, random_state=42))
]
# Define meta-model
meta_model = LogisticRegression(random_state=42)
# Create stacking classifier
stacking = StackingClassifier(
estimators=base_models,
final_estimator=meta_model,
cv=5 # Use CV to generate meta-features
)
stacking.fit(X_train_scaled, y_train)
stacking_acc = stacking.score(X_test_scaled, y_test)
glue('stacking-acc', f'{stacking_acc:.3f}', display=False)
# Compare all ensemble methods
ensemble_comparison = {
'Best Single Model': max(lr_acc, rf_acc, svm_acc),
'Bagging': bagging_acc,
'Random Forest': rf_acc,
'Gradient Boosting': gb_acc,
'Voting (Soft)': soft_acc,
'Stacking': stacking_acc
}
display(pd.DataFrame([
{'Method': name, 'Test Accuracy': f'{score:.3f}'}
for name, score in ensemble_comparison.items()
]))
# Visualize
plt.figure(figsize=(12, 6))
names = list(ensemble_comparison.keys())
scores = list(ensemble_comparison.values())
colors = plt.cm.viridis(np.linspace(0, 1, len(names)))
bars = plt.bar(range(len(names)), scores, color=colors, alpha=0.8,
edgecolor='black', linewidth=1.5)
plt.xticks(range(len(names)), names, rotation=45, ha='right')
plt.ylabel('Test Accuracy', fontsize=12)
plt.title('Complete Ensemble Methods Comparison',
fontsize=13, fontweight='bold')
plt.grid(True, alpha=0.3, axis='y')
plt.ylim([0.90, 1.0])
for i, score in enumerate(scores):
plt.text(i, score + 0.002, f'{score:.3f}',
ha='center', va='bottom', fontweight='bold', fontsize=10)
plt.tight_layout()
plt.show()
| Method | Test Accuracy | |
|---|---|---|
| 0 | Best Single Model | 0.988 |
| 1 | Bagging | 0.947 |
| 2 | Random Forest | 0.936 |
| 3 | Gradient Boosting | 0.947 |
| 4 | Voting (Soft) | 0.982 |
| 5 | Stacking | 0.982 |
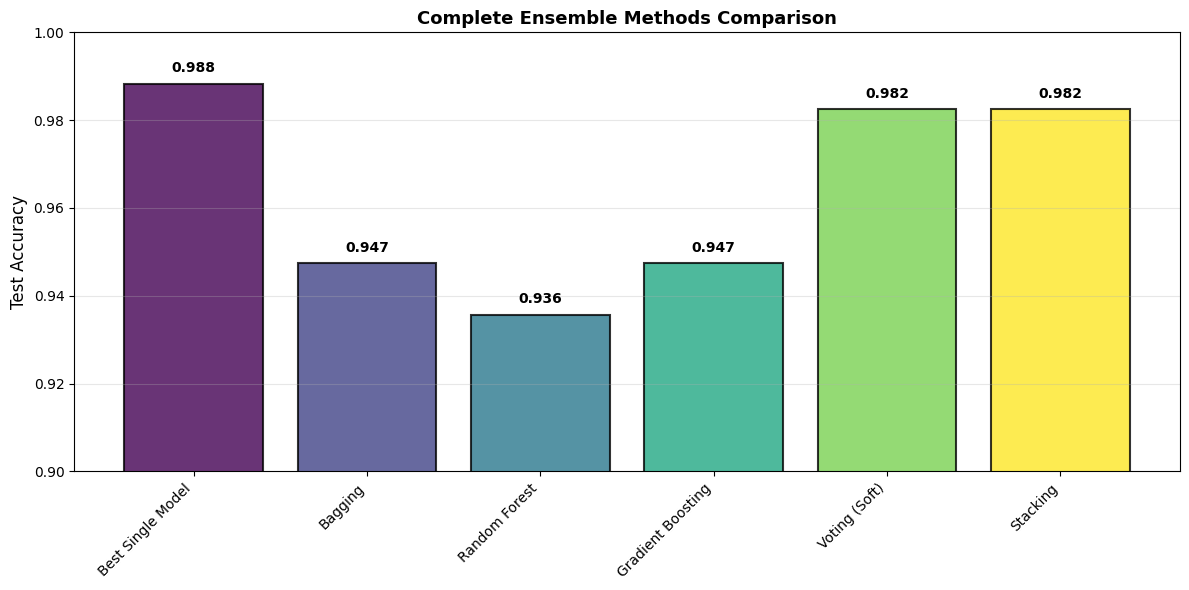
6.4.5.9. Choosing an Ensemble Method#
Method |
When to Use |
|---|---|
Random Forest |
Default for tabular data; good out-of-box performance; fast parallel training; feature importances |
Gradient Boosting |
Maximum performance; willing to tune hyperparameters and train sequentially; use XGBoost/LightGBM/CatBoost in production |
Voting |
Have diverse well-performing models from different algorithm families |
Stacking |
Maximum performance in competitions; have computational resources and can afford complexity |
Bagging |
High-variance base model; want to reduce overfitting; need parallel training |
Rule of thumb: Start with Random Forest → try Gradient Boosting if you need more → use Stacking for competitions.
6.4.5.10. Modern Gradient Boosting: XGBoost, LightGBM, CatBoost#
Production-grade boosting libraries:
XGBoost: Most popular, well-optimized
LightGBM: Fastest, handles large data
CatBoost: Best for categorical features
Library |
Strengths |
Notes |
|---|---|---|
XGBoost |
Most popular in competitions; regularization built-in; handles missing values; parallel tree construction |
|
LightGBM |
Fastest training; leaf-wise tree growth; best for large datasets; low memory |
|
CatBoost |
Best for categorical features; ordered boosting; good defaults; GPU support |
|
Example usage:
from xgboost import XGBClassifier
xgb = XGBClassifier(n_estimators=100, learning_rate=0.1)
xgb.fit(X_train, y_train)
6.4.5.11. Connection to Fundamentals#
Concept |
How Ensembles Relate |
|---|---|
Bias-Variance Trade-off |
Bagging reduces variance; Boosting reduces bias and variance |
Overfitting |
Averaging/voting smooths predictions → more robust than single models |
Model Complexity |
Ensembles are more complex but generalize better |
Computational Cost |
Bagging is parallel (fast); Boosting is sequential (slower) |
Interpretability |
Less interpretable, but feature importances still extractable |
No Free Lunch |
Ensembles excel on tabular data; deep learning often better for images/text |
6.4.5.12. Key Takeaways#
Important
Remember These Points:
Why Ensembles Work
Different models make different errors
Combining reduces variance
Diversity is key
Bagging
Parallel training
Reduces variance
Random Forest = best bagging method
Boosting
Sequential training
Reduces bias + variance
Gradient Boosting often best performer
Random Forest
Default choice for tabular data
Good out-of-box performance
Parallel, fast training
Gradient Boosting
Maximum performance
Needs hyperparameter tuning
Use XGBoost/LightGBM in production
Stacking
Most powerful but complex
Use in competitions
Meta-model combines base models
Practical Advice
Start with Random Forest
Try Gradient Boosting if need more
Stack if in competition
6.4.5.13. Coming Up Next#
Now that you understand ensemble methods, you’re ready for:
Feature Importance: Understanding what models learn
Model compression: Making ensembles faster
Ensemble methods are the secret weapon of data science competitions!
Warning
Common Mistakes:
Not using ensembles → Missing easy performance gains
Using too many weak models → Diminishing returns after ~100-200
Forgetting to tune → Default hyperparameters suboptimal
Using bagging for linear models → Doesn’t help (already low variance)
Not scaling for SVM/LR in ensemble → Different scales hurt
Boosting with too high learning rate → Overfitting
Stacking without CV → Data leakage in meta-features
Ignoring computational cost → Ensembles slower at inference