6.2.1.8. Boosting#
All the ensemble methods on the Ensemble Methods page train their models in parallel and then average. Boosting is fundamentally different: models are trained sequentially, each one focused on correcting the mistakes of the ones before it.
The analogy is a student who reviews past exam papers: instead of preparing broadly, they prioritise the questions they got wrong last time. Each successive weak learner becomes progressively better at the hard cases.
This sequential correction means boosting reduces bias (the model becomes more accurate with each round), while parallel averaging primarily reduces variance. The cost is that boosting is more prone to overfitting if run for too many rounds.
Two algorithms dominate:
Algorithm |
How the next model is targeted |
|---|---|
AdaBoost |
Re-weights training samples - hard samples get higher weight |
Gradient Boosting |
Fits the next model to the residuals (pseudo-gradients) of the current ensemble |
AdaBoost#
The Math#
AdaBoost trains a sequence of weak learners \(h_1, h_2, \ldots, h_M\) (typically very shallow decision trees - “stumps”). After each step, training samples that were predicted incorrectly receive higher weights so the next learner focuses on them:
Initialise equal sample weights \(w_i = \frac{1}{n}\).
For \(m = 1, \ldots, M\):
Train weak learner \(h_m\) on weighted samples.
Compute weighted error: \(\varepsilon_m = \frac{\sum_i w_i \cdot \mathbf{1}[\text{error}_i > \tau]}{\sum_i w_i}\).
Compute learner weight: \(\alpha_m = \frac{1}{2}\ln\!\frac{1-\varepsilon_m}{\varepsilon_m}\).
Update sample weights: increase for hard samples, decrease for easy ones.
Final prediction: \(F(x) = \sum_{m=1}^{M} \alpha_m\, h_m(x)\).
The key difference from bagging: well-performing learners get higher \(\alpha_m\) and dominate the final vote.
Gradient Boosting#
The Math#
Gradient Boosting takes a more general view. It frames boosting as gradient descent in function space: at each step, fit a new weak learner \(h_m\) to the negative gradient of the loss with respect to the current prediction.
For MSE loss, the negative gradient is simply the residual \(y_i - F_{m-1}(x_i)\), so the update rule is:
where \(h_m\) is fitted to the residuals \(r_i = y_i - F_{m-1}(x_i)\) and \(\eta\) is the learning rate (called shrinkage).
Lower learning rates require more rounds but generally generalise better - the trade-off is controlled by learning_rate and n_estimators.
In scikit-learn#
from sklearn.ensemble import AdaBoostRegressor, GradientBoostingRegressor
ada = AdaBoostRegressor(
estimator=DecisionTreeRegressor(max_depth=3),
n_estimators=100,
learning_rate=0.1,
random_state=42
)
gb = GradientBoostingRegressor(
n_estimators=200,
learning_rate=0.05,
max_depth=3,
random_state=42
)
Key hyperparameters:
Hyperparameter |
Role |
|---|---|
|
Number of boosting rounds - more can overfit |
|
Shrinkage per round - lower → more rounds needed, better generalisation |
|
Depth of each weak learner - shallow trees (2–5) are standard |
|
The weak learner type |
Example#
ada = AdaBoostRegressor(
estimator=DecisionTreeRegressor(max_depth=3),
n_estimators=100, learning_rate=0.1, random_state=42
)
gb = GradientBoostingRegressor(
n_estimators=200, learning_rate=0.05, max_depth=3, random_state=42
)
ada.fit(X_train, y_train)
gb.fit(X_train, y_train)
for name, model in [("AdaBoost", ada), ("Gradient Boosting", gb)]:
tr = r2_score(y_train, model.predict(X_train))
te = r2_score(y_test, model.predict(X_test))
rmse = np.sqrt(mean_squared_error(y_test, model.predict(X_test)))
print(f"{name:<22} Train R²={tr:.3f} Test R²={te:.3f} RMSE={rmse:.1f}")
AdaBoost Train R²=0.831 Test R²=0.646 RMSE=105.7
Gradient Boosting Train R²=0.997 Test R²=0.838 RMSE=71.5
AdaBoost achieves test \(R^2\) = 0.646 (RMSE = 105.7). Gradient Boosting achieves 0.838 (RMSE = 71.5). Gradient Boosting generally outperforms AdaBoost because it can directly minimise the regression loss function.
Staged Learning Curves - When Does Overfitting Start?#
Because boosting builds the model iteratively, we can inspect performance at every intermediate round - a powerful diagnostic:
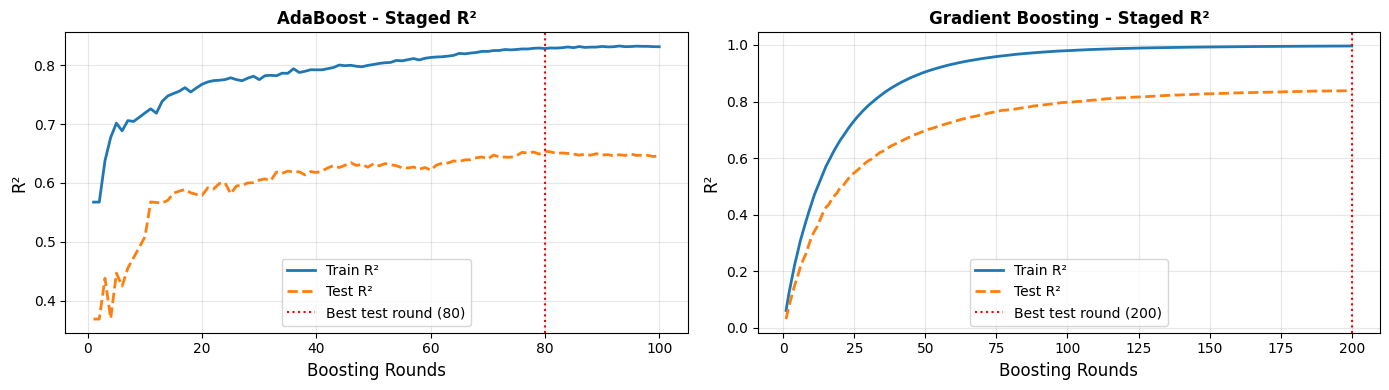
For AdaBoost, the best test performance is reached at round 80. Gradient Boosting peaks at round 200. Both eventually overfit if run for too many rounds - the staged learning curves make this visible and help you choose the right number of estimators.
Learning Rate vs Number of Estimators Trade-off#
| learning_rate | n_estimators | Train R² | Test R² | |
|---|---|---|---|---|
| 0 | 0.50 | 50 | 0.999 | 0.800 |
| 1 | 0.10 | 200 | 0.999 | 0.842 |
| 2 | 0.05 | 400 | 0.999 | 0.848 |
| 3 | 0.01 | 1000 | 0.997 | 0.837 |
Smaller learning rates with more rounds consistently match or beat larger learning rates - at the cost of training time. This is the standard shrinkage trade-off in boosting.
Prediction vs Ground Truth#
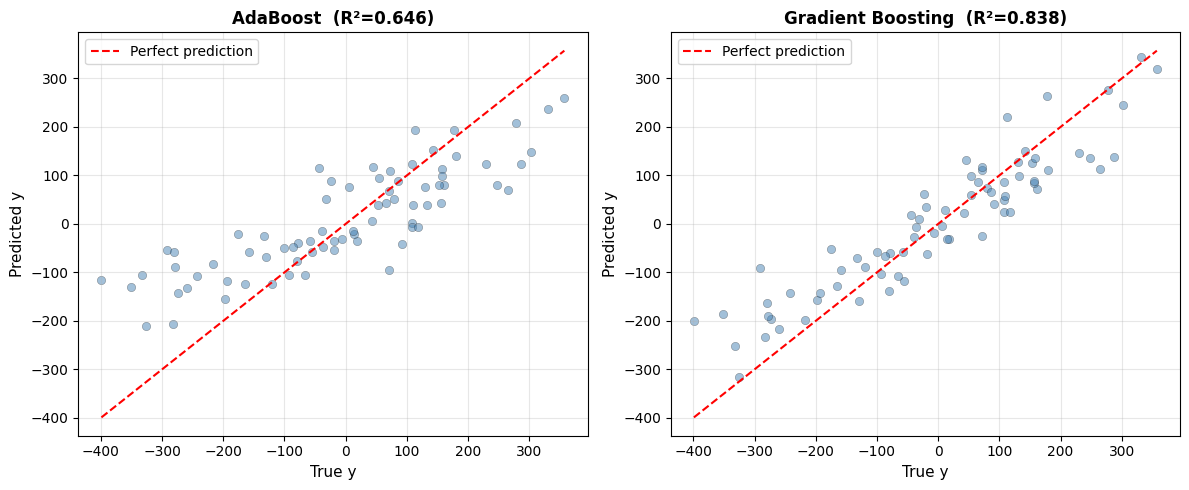
Points clustering tightly around the diagonal indicate accurate predictions. Gradient Boosting’s tighter cluster reflects its higher \(R^2\).
Strengths and Weaknesses#
Strengths |
Often achieves top performance on tabular data; reduces bias with each round; staged predictions make overfitting transparent |
Weaknesses |
Sequential training is slower than Random Forest; more hyperparameters to tune; sensitive to outliers (especially AdaBoost) |
Tip
For most competitions and production settings, Gradient Boosting (or its optimised variants XGBoost, LightGBM, CatBoost) is the strongest off-the-shelf regressor. Start with learning_rate=0.05 and tune n_estimators using early stopping on a validation set.