6.1.6. The Bias-Variance Tradeoff#
In the previous section, we explored underfitting and overfitting at a practical level. Now we’ll dig deeper into why this tradeoff exists. The answer lies in one of the most elegant concepts in machine learning: the bias-variance tradeoff.
Understanding this concept will transform you from someone who can train models to someone who truly understands what’s happening under the hood. This is where intuition meets theory!
6.1.6.1. The Fundamental Question#
When your model makes a prediction error, where does that error come from? Is it because:
Your model is too simple? (bias)
Your model is too sensitive to training data? (variance)
The data itself is noisy? (irreducible error)
It turns out all three contribute to your total error, and there’s a beautiful mathematical relationship between them.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.pipeline import make_pipeline
from myst_nb import glue
# Set random seed for reproducibility
np.random.seed(42)
Total Error = Bias² + Variance + Irreducible Error
Think of it as:
Bias: How far off is your model on average?
Variance: How much does your model jump around?
Irreducible: Noise we can’t eliminate
6.1.6.2. Bias: Error from Wrong Assumptions#
Bias is the error introduced by approximating a complex real-world problem with a simplified model.
Think of it this way:
You’re trying to catch a baseball
But you assume it travels in a straight line (ignoring gravity)
Bias = How far off you are on average due to this wrong assumption
In machine learning:
High bias = model is too simple = underfitting
The model makes systematic errors because it can’t capture the true pattern
def true_function(x):
"""The true underlying pattern (unknown in real problems!)"""
return 5 + 2*x - 0.3*x**2
# Generate data
X = np.linspace(0, 10, 100).reshape(-1, 1)
y_true = true_function(X.ravel())
y_noisy = y_true + np.random.normal(0, 2, 100)
# Train high-bias model
model_high_bias = LinearRegression()
model_high_bias.fit(X, y_noisy)
y_pred_bias = model_high_bias.predict(X)
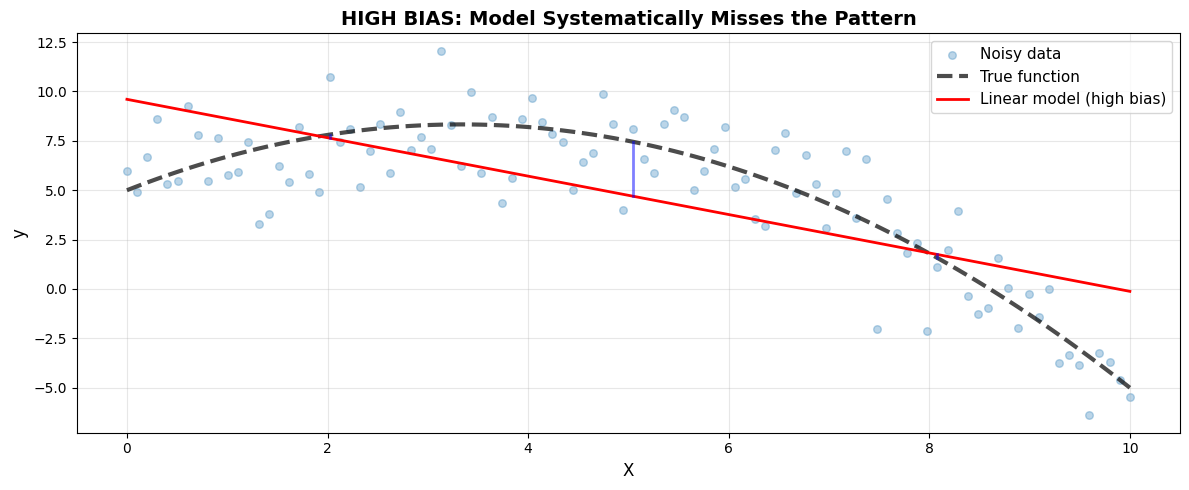
Bias² (squared average error): 5.25
Notice: Linear model ALWAYS underestimates at the edges. This systematic error is BIAS.
Characteristics of High Bias#
High Bias Symptoms:
Model too simple for the problem
Underfits both training and test data
High training error
High test error
Model makes systematic, predictable errors
Adding more data doesn’t help much
Examples:
Linear regression on non-linear data
Shallow decision tree on complex data
Simple rule-based system for complex task
6.1.6.3. Variance: Error from Sensitivity to Training Data#
Variance is the error from the model being too sensitive to small fluctuations in the training data.
Think of it this way:
You’re trying to draw the “average” face
But you only saw 3 people, and one had a huge nose
Now your “average” face has a huge nose!
Variance = How much your answer changes based on which examples you saw
In machine learning:
High variance = model is too flexible = overfitting
The model changes dramatically with different training sets
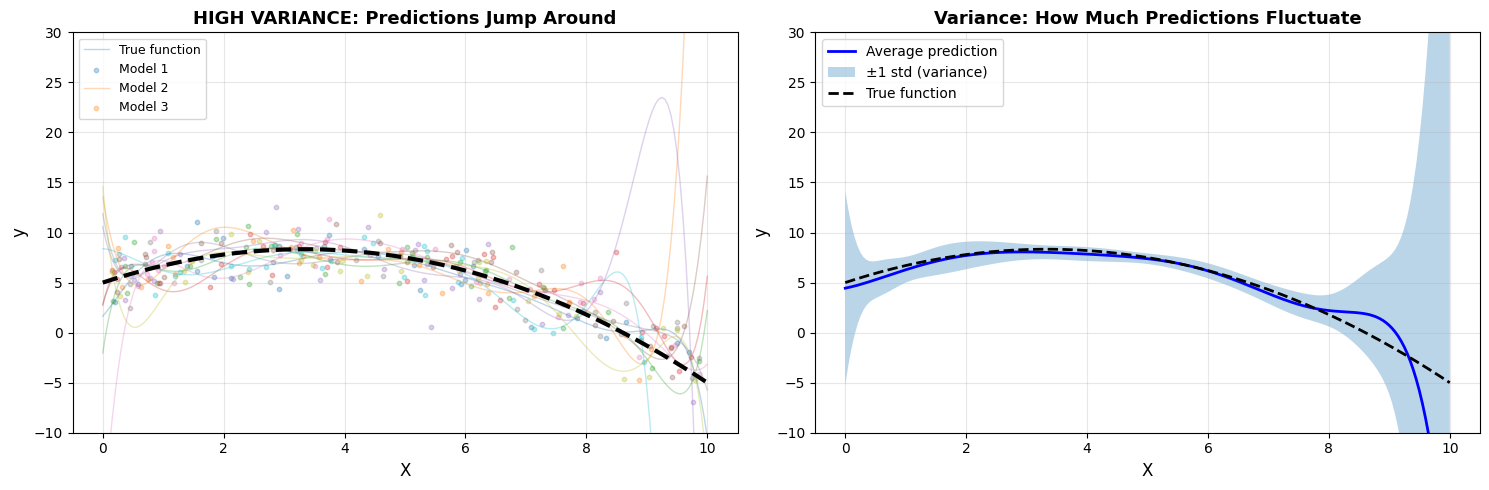
Average variance across predictions: 237.15
Notice: Different training sets → wildly different predictions. This sensitivity is VARIANCE.
Characteristics of High Variance#
High Variance Symptoms:
Model too complex/flexible for the data
Overfits training data
Low training error (fits training data perfectly)
High test error (fails on new data)
Predictions change drastically with different training sets
Large gap between train and test performance
Examples:
High-degree polynomial on small dataset
Deep decision tree without pruning
Neural network with too many parameters
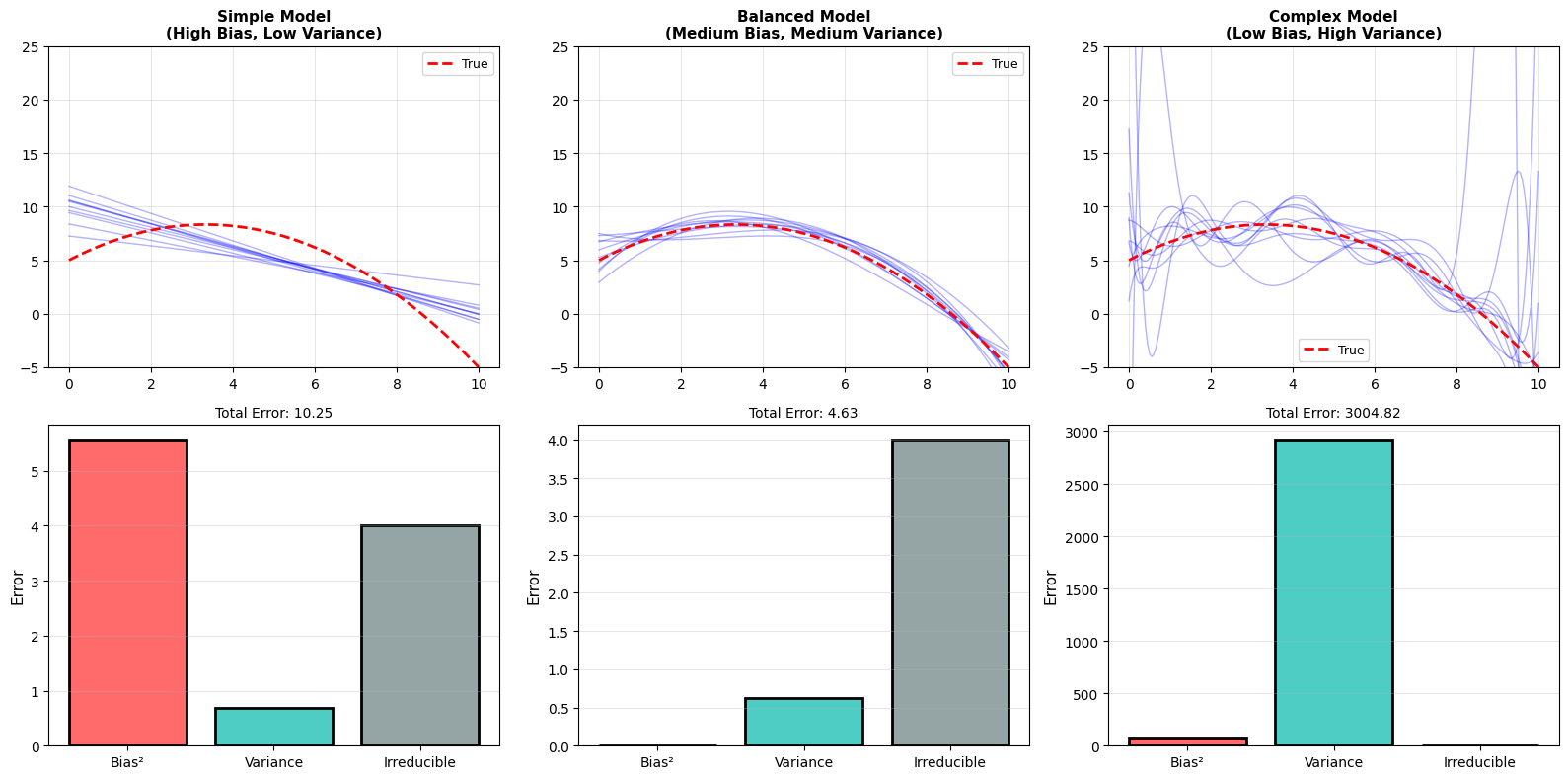
6.1.6.4. The Tradeoff: You Can’t Have Both Low#
Here’s the fundamental insight: You cannot simultaneously minimize both bias and variance.
Why? Because they pull in opposite directions:
Reducing bias → Add complexity → Increases variance
Reducing variance → Simplify model → Increases bias
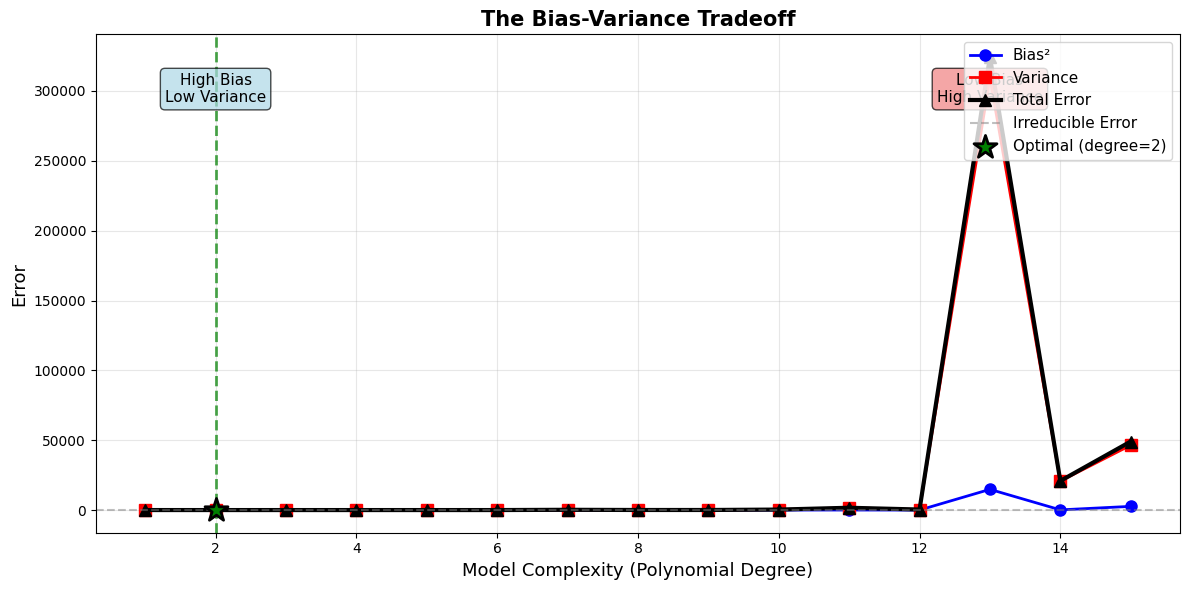
Key Observations:
As complexity increases, bias² decreases (better fit)
As complexity increases, variance increases (less stable)
Total error = Bias² + Variance + Irreducible
Optimal complexity: 2 (minimizes total error)
Can’t reduce both simultaneously - it’s a TRADEOFF
The Mathematical Decomposition#
Important
Error Decomposition Formula:
For a model’s prediction \(\hat{f}(x)\) compared to true value \(y\):
Where:
Bias² = \((E[\hat{f}(x)] - f(x))^2\)
How far is the average prediction from the truth?
Variance = \(E[(\hat{f}(x) - E[\hat{f}(x)])^2]\)
How much do predictions vary across training sets?
Irreducible Error = Noise in the data itself (cannot be reduced)
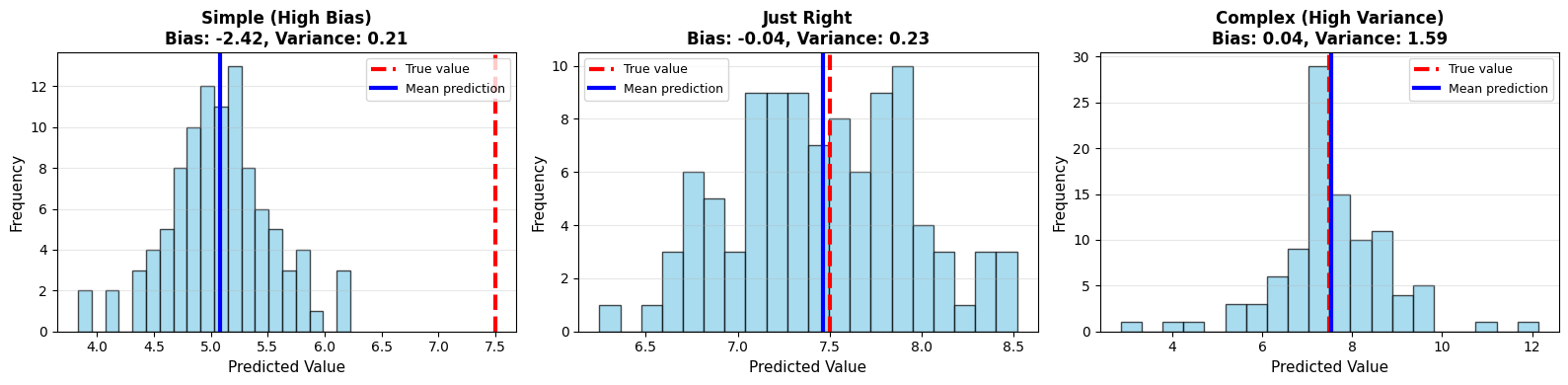
At x = 5:
True value: 7.50
Simple model (degree 1):
Mean prediction: 5.08
Bias: -2.42
Variance: 0.21
Optimal model (degree 2):
Mean prediction: 7.46
Bias: -0.04
Variance: 0.23
Complex model (degree 10):
Mean prediction: 7.54
Bias: 0.04
Variance: 1.59
6.1.6.5. Connection to Model Complexity#
The bias-variance tradeoff is intimately connected to model complexity:
Model Type |
Complexity |
Bias |
Variance |
Best For |
|---|---|---|---|---|
Simple (linear) |
Low |
High |
Low |
Simple patterns, small data |
Medium (quadratic) |
Medium |
Medium |
Medium |
Moderate patterns, medium data |
Complex (high-degree) |
High |
Low |
High |
Complex patterns, large data |
6.1.6.6. The No Free Lunch Theorem#
The bias-variance tradeoff leads to an important realization: There is no universally best model.
The No Free Lunch Theorem states: Averaged over all possible problems, every algorithm performs equally well.
What this means practically:
Simple models win on simple problems
Complex models win on complex problems
You need to match model complexity to problem complexity
Always validate on your specific data!
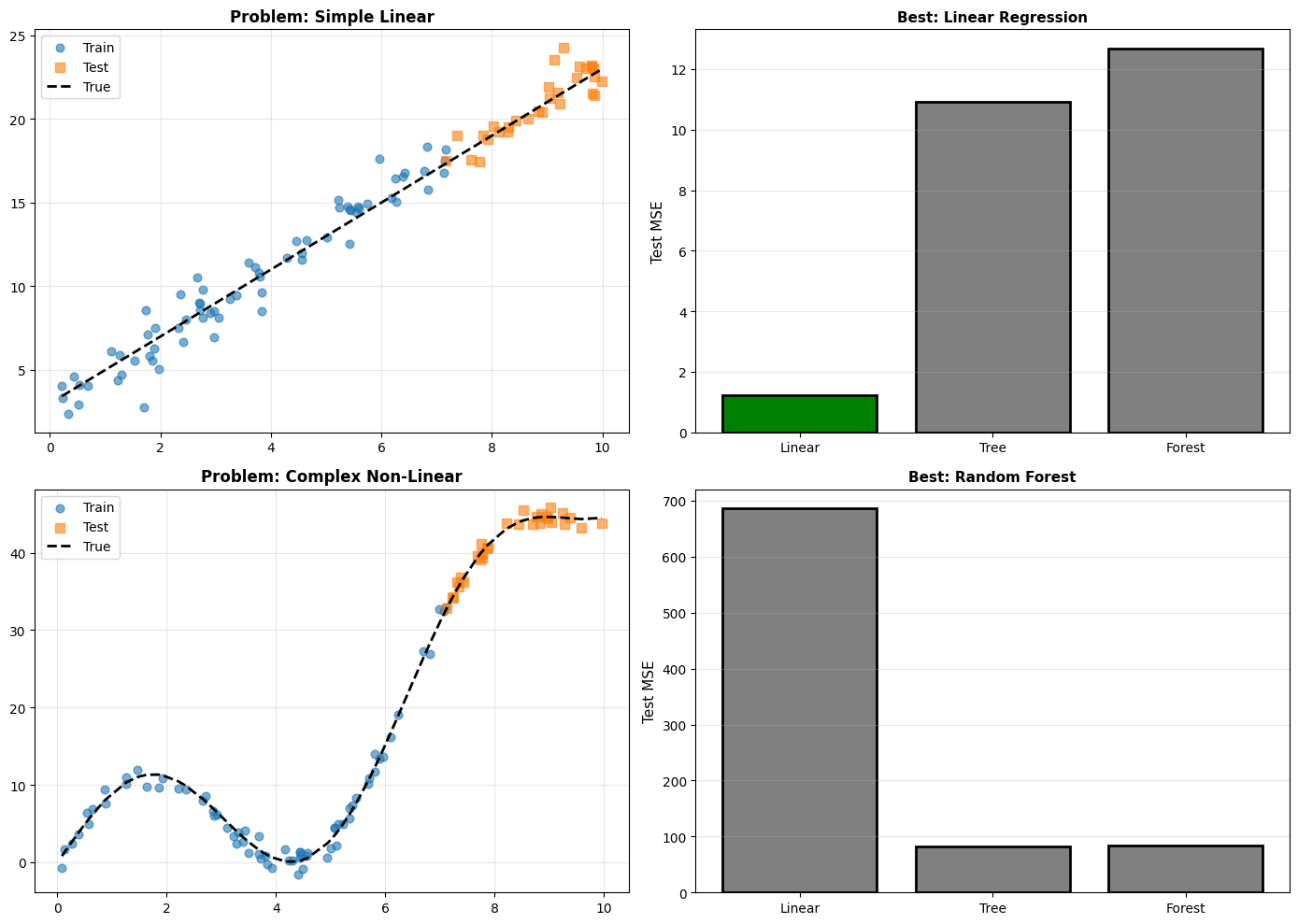
No Free Lunch Theorem in Action:
Linear problem → Linear model wins
Complex problem → Complex model wins
No single ‘best’ model for all problems
Must validate on YOUR specific data!
6.1.6.7. Practical Implications#
Tip
How to Navigate the Bias-Variance Tradeoff:
Start simple - Begin with low-complexity models
Monitor both - Track training AND validation error
Increase complexity gradually - Add just enough
Use validation - Catch overfitting early
Regularization helps - Controls variance without sacrificing too much bias
More data helps variance - Large datasets allow complex models
Feature engineering helps bias - Better features reduce need for complexity
Practical Decision Guide:
Situation 1: High training error + High test error
High BIAS (underfitting)
Solution: Increase model complexity
Example: Try polynomial features, deeper tree, more layers
Situation 2: Low training error + High test error
High VARIANCE (overfitting)
Solution: Reduce complexity OR get more data
Example: Add regularization, prune tree, dropout, early stopping
Situation 3: Large gap between training and test
High VARIANCE
Model is memorizing rather than learning
Situation 4: Both errors decreasing with more data
You’re on the right track!
More data will help
Situation 5: Both errors plateau despite more data
High BIAS
Need more model capacity, not more data
Warning
Don’t Oversimplify!
While the bias-variance tradeoff is a powerful mental model, remember:
Real models have many sources of error
The tradeoff isn’t always perfect (regularization can help both!)
Always validate empirically on your data