Formal Machine Interpretation of Mixtec Codices
In this project, we study the codices of a people from pre-colonial and early colonial mesoamerica called the Mixtec, a name sharing etymology with the modern country of Mexico where many of their artifacts were found.
Mixtec codices are written semasiographic script that is not directly interpreted into the language of the Mixtec people but interpreted directly. Many sources liken them to comic books or storyboards. Like Japanese manga, the scenes depicted are typically read right-to-left in an order determined by red lines drawn along side the pictoral content.
We develop a parser and interpreter for the Mixtec codices capable of parsing a string of tokens inferred by a scanning and tokenization process into an English interpretation of scenes. The current parser and interpreter are equipped to handle a subset of the scene types shown in the codices for which there is a reconizable pattern of glyphs (drawn figures) and for which uncontroversial interpretations exist.
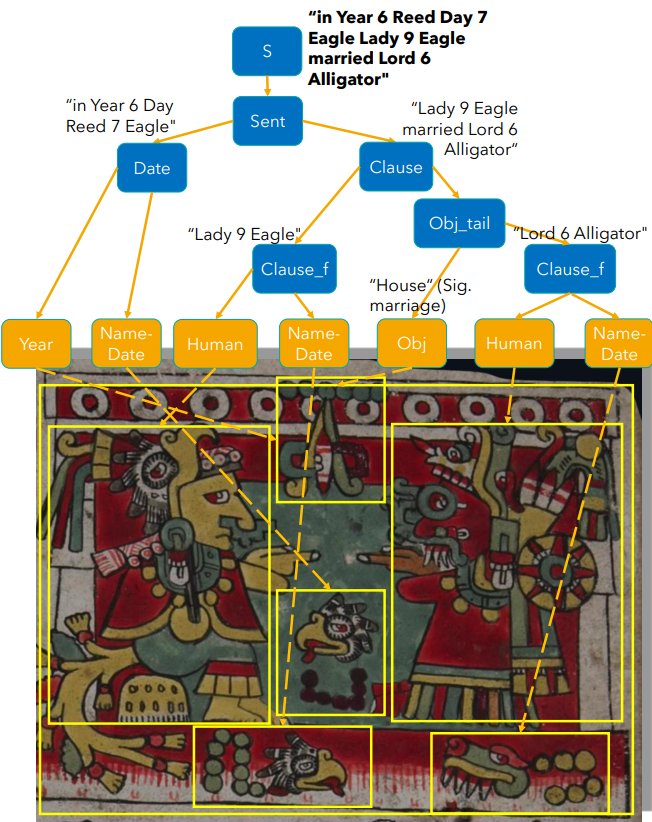
The image below is the full example of an Abstract Syntax Tree (AST) produced by our parser and the steps used to interpret the scene.
Demo
Try the parser and interpreter yourself in our Mixtec parser demo.
Links and Resources
People
Repo(s) (Contact UF Data Studio admin. for access.)
Publications
- Christopher Driggers-Ellis, Gabriel Ayoubi, Girish Salunke, Christan Grant. Formal Machine Interpretation for the Semasiographic Mixtec Codices of Precolonial and Early Colonial Mesoamerica. The 4th Workshop on Advances in Language and Vision Research (ALVR) at ACL. San Diego, California, USA. 2026. anthology | poster | demo