The UF Data Studio at ACL 2026 in San Diego

Hero photo of San Diego by Frank McKenna, from the ACL 2026 website.
What we are bringing to San Diego
The UF Data Studio is heading to ACL 2026 in San Diego! I am proud of the work my students are presenting. The 64th Annual Meeting of the Association for Computational Linguistics runs July 2 to 7, and we have three pieces of work on the program. One paper asks whether audio models reason over speech or only transcribe it. Another reads the vision-and-language script of the Mixtec codices. The third translates for Indigenous languages of the Americas, and it won its shared task.
Chibuzor Okocha, Christopher Driggers-Ellis, Gabriel Ayoubi, Girish Salunke, Aashish Dhawan, and Dzmitry Kasinets led these papers, together with my colleague Daisy Zhe Wang. Come find them in San Diego and see what they built.
| Work | Venue | When | Where |
|---|---|---|---|
| Afrispeech Semantics | Findings of ACL | Main conference, July 5–7 | Findings poster session, Grand Hall |
| Mixtec codex interpretation | ALVR workshop | Friday, July 3 | ALVR program, spotlight and poster sessions |
| AmericasNLP shared-task winner | AmericasNLP workshop | Friday, July 3 afternoon | Shared-task results session |
Afrispeech Semantics (Findings of ACL)
Chibuzor Okocha and I ask the following question: do audio language models reason over speech, or do they transcribe and then guess? We built a benchmark that separates the two. It scores models on five semantic and paralinguistic tasks: entailment, consistency, plausibility, accent drift, and accent restraint. Each task withholds the transcript, so the model has to work from the spoken audio itself.
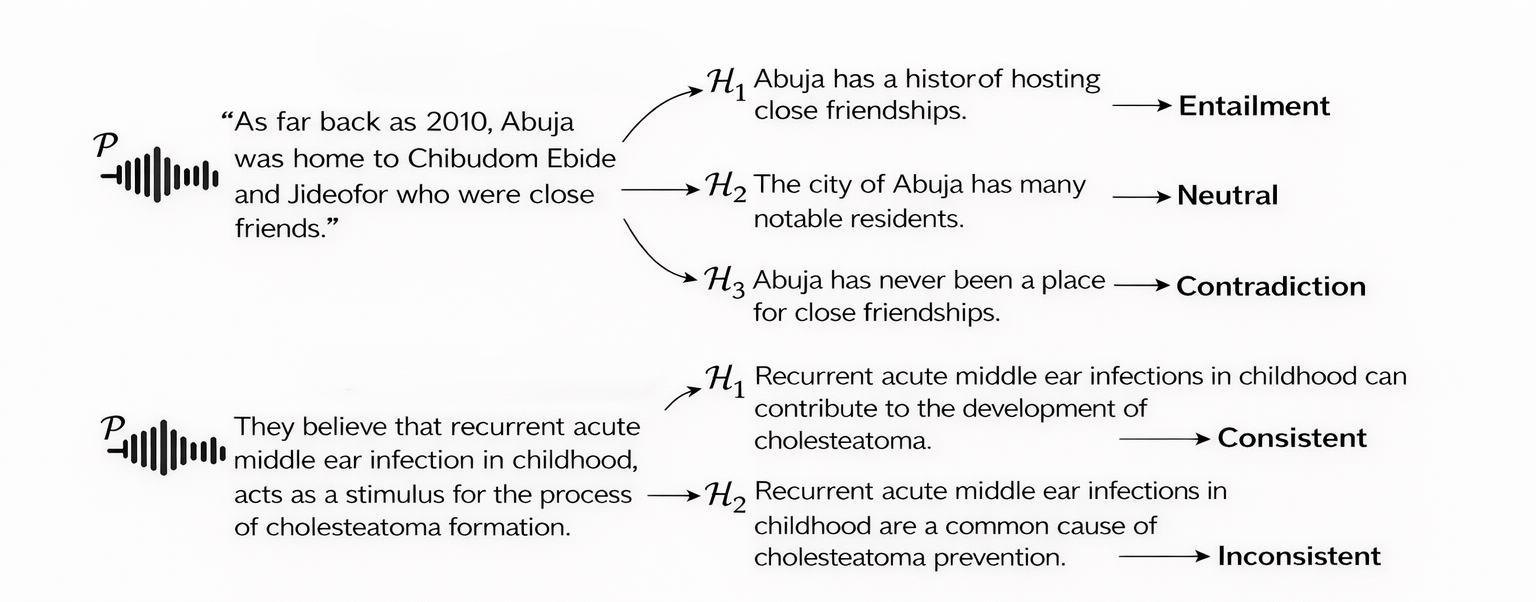
A cascade won. Running Whisper for recognition and then Qwen2.5-7B for reasoning reached the top macro F1 on the medical split and beat the native end-to-end audio models. Accent variation still moved predictions more than it should, the exact failure the benchmark was built to expose.
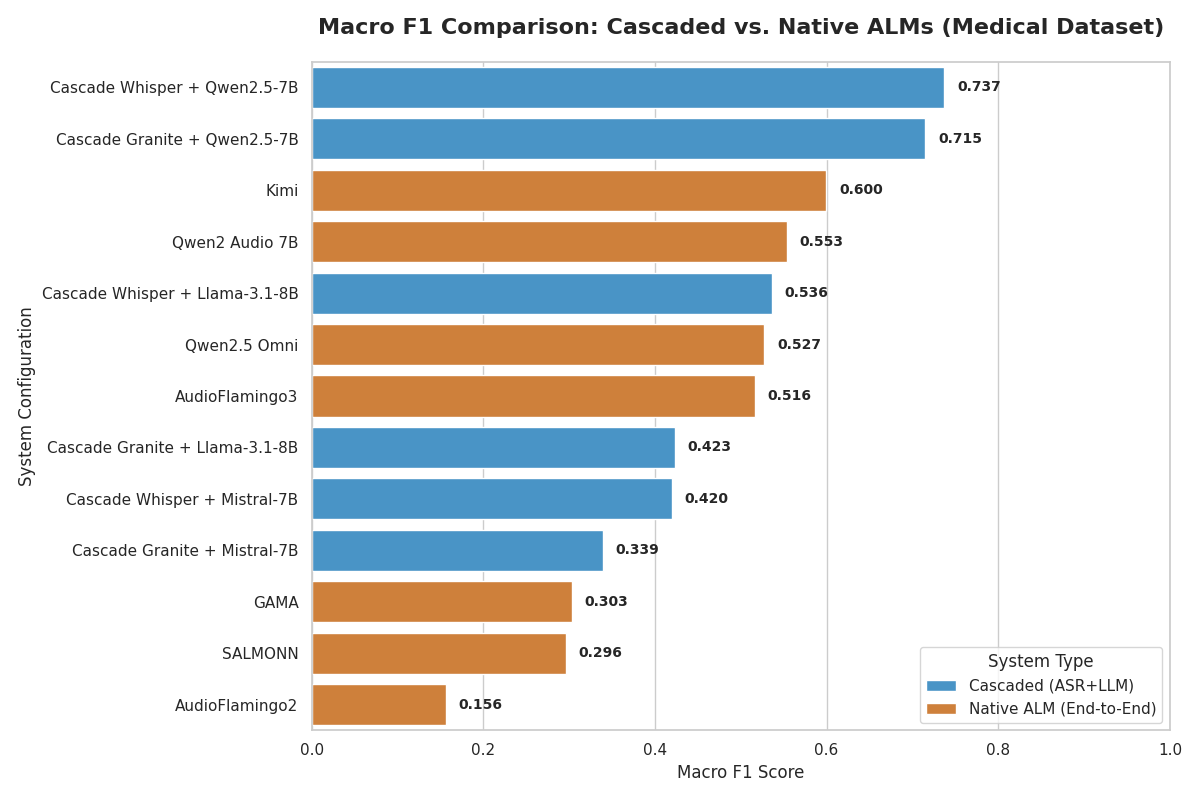
Look for the poster in the Findings track during the main conference, July 5 to 7, in the Grand Hall. You can read it now on the ACL Anthology or arXiv.
Reading the Mixtec Codices (ALVR workshop)
"Formal Machine Interpretation for the Semasiographic Mixtec Codices of Precolonial and Early Colonial Mesoamerica" is our paper at the 4th Workshop on Advances in Language and Vision Research (ALVR). Christopher Driggers-Ellis, Gabriel Ayoubi, Girish Salunke, and I wrote it.
The Mixtec kept their history in codices. These painted books are read as pictures, not as sound or letters, and a reader follows the red guide lines that thread through each page. We build a parser and interpreter that takes a string of tokens from a scanned scene and returns an English reading of what the scene shows.
The figure below shows the system at work. It parses a marriage scene from the Codex Zouche-Nuttall into a syntax tree and grounds each node back in the painting. The reading it recovers is "in Year 6 Reed Day 7 Eagle, Lady 9 Eagle married Lord 6 Alligator."
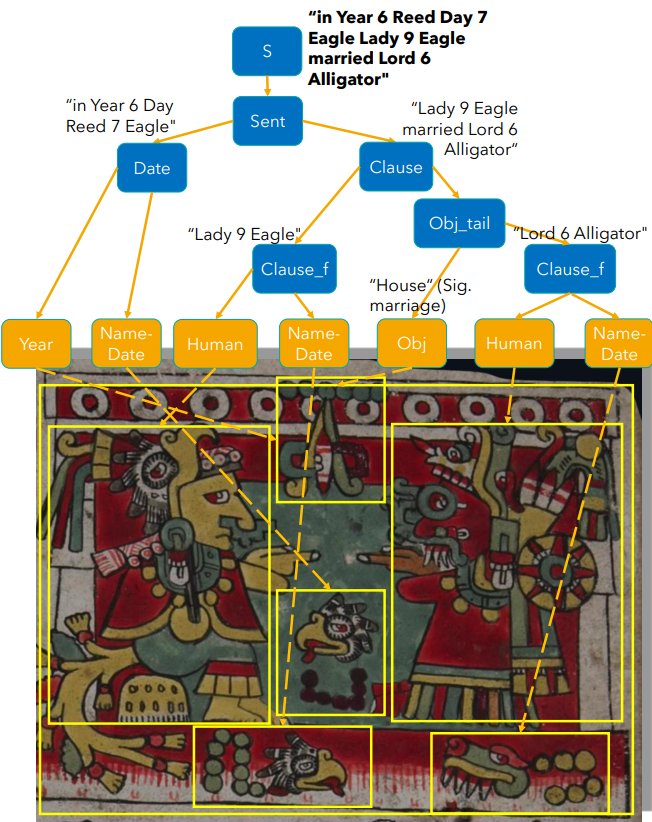
You can try the system yourself in our Mixtec parser demo and read more on the project page. ALVR runs all day Friday, July 3, with spotlight talks late in the morning and a poster session in the afternoon. Read the paper on the ACL Anthology.
An overall win at the AmericasNLP shared task
Our submission to the AmericasNLP 2026 shared task on cultural image captioning finished first overall! 🎉 Team Gators is a collaboration between the UF Data Studio and the Data Science Research Lab. Aashish Dhawan, Christopher Driggers-Ellis, Dzmitry Kasinets, Daisy Zhe Wang, and I wrote the system paper, "Retrieval-Augmented Long-Context Translation for Cultural Image Captioning."
The task asks for captions of culturally situated images in five Indigenous languages: Guaraní, Yucatec Maya, Orizaba Nahuatl, Wixarika, and Bribri. Our pipeline runs in two stages. It first writes a Spanish caption with Qwen2.5-VL, then produces the target-language caption with Gemini 2.5 Flash from retrieved, many-shot examples. The Gators system lifted dev-set scores over the baseline by 164.1% for Bribri, 131.7% for Guaraní, and 122.6% for Orizaba Nahuatl, and its test-set gains stayed above 150% for Bribri and Orizaba Nahuatl. Team Gators placed second in all five language tracks. The organizers ranked systems by summed rank points, so that steady placement earned the highest total, 20 points against 14 for the runner-up, and the overall win.
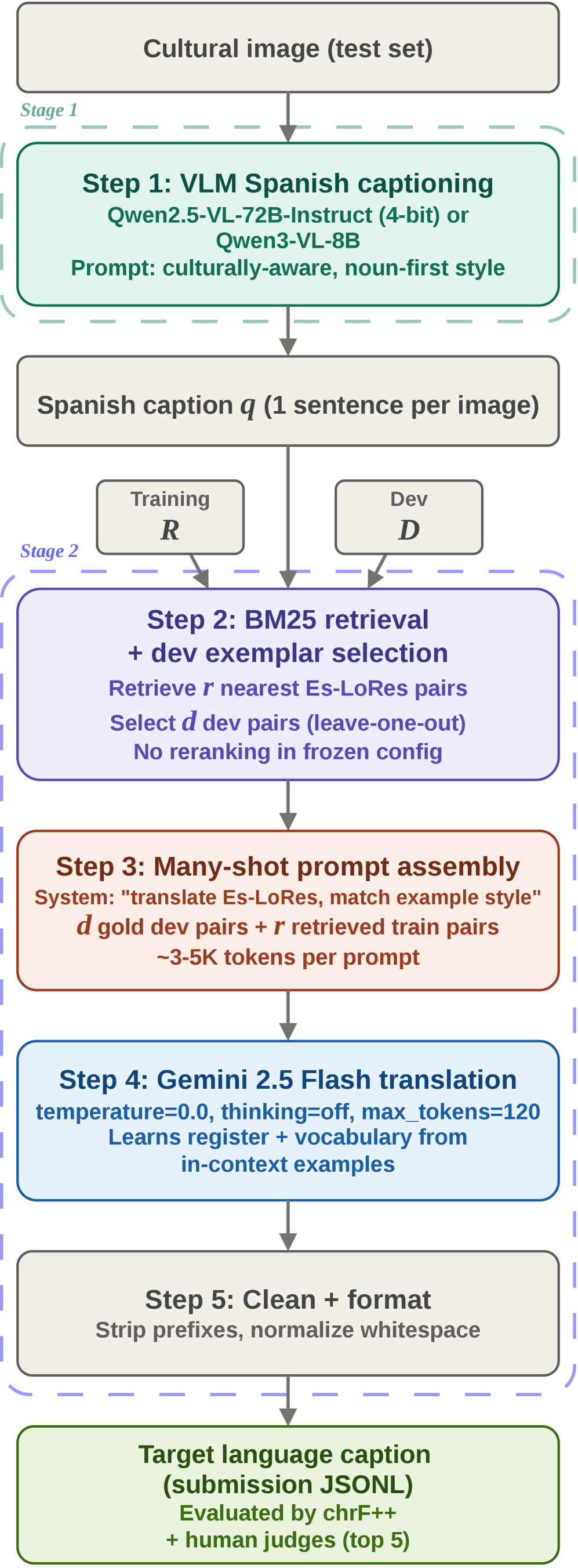
The work grows out of the translation research we presented at LoResMT this spring on synthetic data and language-specific preprocessing for low-resource languages. AmericasNLP is a half-day workshop on the afternoon of Friday, July 3, and the shared-task results appear in that session. Aashish tells the full story on the DSR lab blog, and you can read the paper on arXiv and the shared-task description.
Come say hello
This is the work we are proud to show in San Diego. Chibuzor, Christopher, Gabriel, Girish, Aashish, and Dzmitry will be on the floor and would welcome a conversation about audio reasoning, semasiographic writing, or low-resource translation. Stop by the ALVR and AmericasNLP sessions on Friday, July 3, and catch the Afrispeech poster during the main conference.
For more about our work, visit our homepage at ufdatastudio.com and browse our publications.