Workshop Trip to Chicago

I spent a few energizing days at the Toyota Technological Institute at Chicago (TTIC) for a workshop centered on speech foundation models (SFMs) and audio-language models (ALMs). I presented my AfriVox poster and soaked in a whirlwind of ideas about the future of speech AI.
Highlights
Keynote Themes that Stuck During the workshop, I attended a keynote talk by Hung-yi Lee (李宏毅), Professor in the Departments of Electrical Engineering and Computer Science & Information Engineering at National Taiwan University. He focused on the evolution of Spoken Language Models (SLMs) and how they extend text-based Large Language Models (LLMs) to process and generate speech without losing their core universal capabilities. He walked us through methods to integrate speech comprehension and generation into LLMs, highlighting the challenge of avoiding catastrophic forgetting of existing skills.
He also introduced novel speech representation learning techniques tailored for SLMs and presented intriguing analyses of their internal representations. Beyond the technical details, he shared insights on benchmark evaluations that measure not just transcription accuracy but also instruction-following ability, reasoning strength, and performance in full-duplex dialogue.
My main takeaways were that scaling alone isn’t everything—thoughtful data selection and instruction tuning can achieve competitive results; representation gaps remain a critical hurdle, especially with accents, code-switching, and noisy field recordings; and that evaluation should move beyond leaderboards toward task-grounded, user-centered measures, particularly for safety-critical applications. Hearing this talk sharpened my perspective on what it will take for audio-language models to serve diverse and global communities reliably.
Evaluation & Reproducibility Panel We also had a rich panel session on Evaluation, Benchmarking, and Open Source Models, which went beyond technical metrics and dove into community impact. The discussion emphasized the importance of transparent data cards and deterministic evaluation pipelines (version-pinned code, fixed seeds) to ensure results are reproducible across labs. Panelists urged that evaluations should include granular error analyses—breaking down results by accent, recording environment, and prompt style—rather than relying solely on aggregate scores like WER or BLEU.
There was also a strong call for honest reporting of limitations and disparities, rather than chasing leaderboards. On the open-source front, the panel highlighted how shared baselines and small, easy-to-use starter repositories can lower entry barriers for the community, fostering broader participation and accountability.
Finally, the speakers reflected on the role of open-source in shaping benchmarks and community norms, arguing that fairness, transparency, and honest reporting are as critical as raw model performance.
Modeling Sessions One of the talks that really stood out to me was given by David Harwath from UT Austin, who spoke on Speech Generation and Sound Understanding in the Era of Large Language Models. He showed how LLMs, when extended multimodally, can move beyond text to generate and reason over speech, audio, and even visuals. I was fascinated by his team’s work on VoiceCraft, a neural codec model that not only supports voice cloning and high-quality text-to-speech, but can also directly edit speech waveforms and synchronize them with video for dubbing. He then introduced ParaSpeechCaps, a massive dataset pairing transcribed speech with stylistic captions, which enabled models to synthesize voices controllable by prompts like “a husky, sleepy tone” or “a young British woman speaking with authority.”
Finally, he turned to spatial sound reasoning with SpatialSoundQA and the BAT model, showing how models can now localize and compare multiple sound sources in an environment and reason about them in natural language. For me, this talk captured the sheer range of where speech AI is headed—from personalized, controllable synthesis to reasoning about real-world acoustic spaces—and reinforced the central role of carefully curated datasets and aligned training strategies.
 Training multiple Mistures of Experts, which was used in FlexOlmo.
Training multiple Mistures of Experts, which was used in FlexOlmo.
My Poster: AfriVox
AfriVox: Toward Fairer Benchmarks for African-Accented Speech in ALMs
I introduced AfriVox as my push toward fairer benchmarks for African-accented speech in audio-language models. In practice, I’m curating balanced accent coverage across regions (e.g., West, East, Southern Africa), code-switching patterns, and real-world noise, then aligning tasks—ASR, spoken QA, instruction-following with audio context, and command grounding—so we measure what matters rather than chasing metric soup.
I pair human-centric judgments (intelligibility, task success, helpfulness) with a small set of automated metrics that actually correlate with perception (e.g., WER/CER, where appropriate, plus audio-text similarity or quality scores only when validated against human ratings).
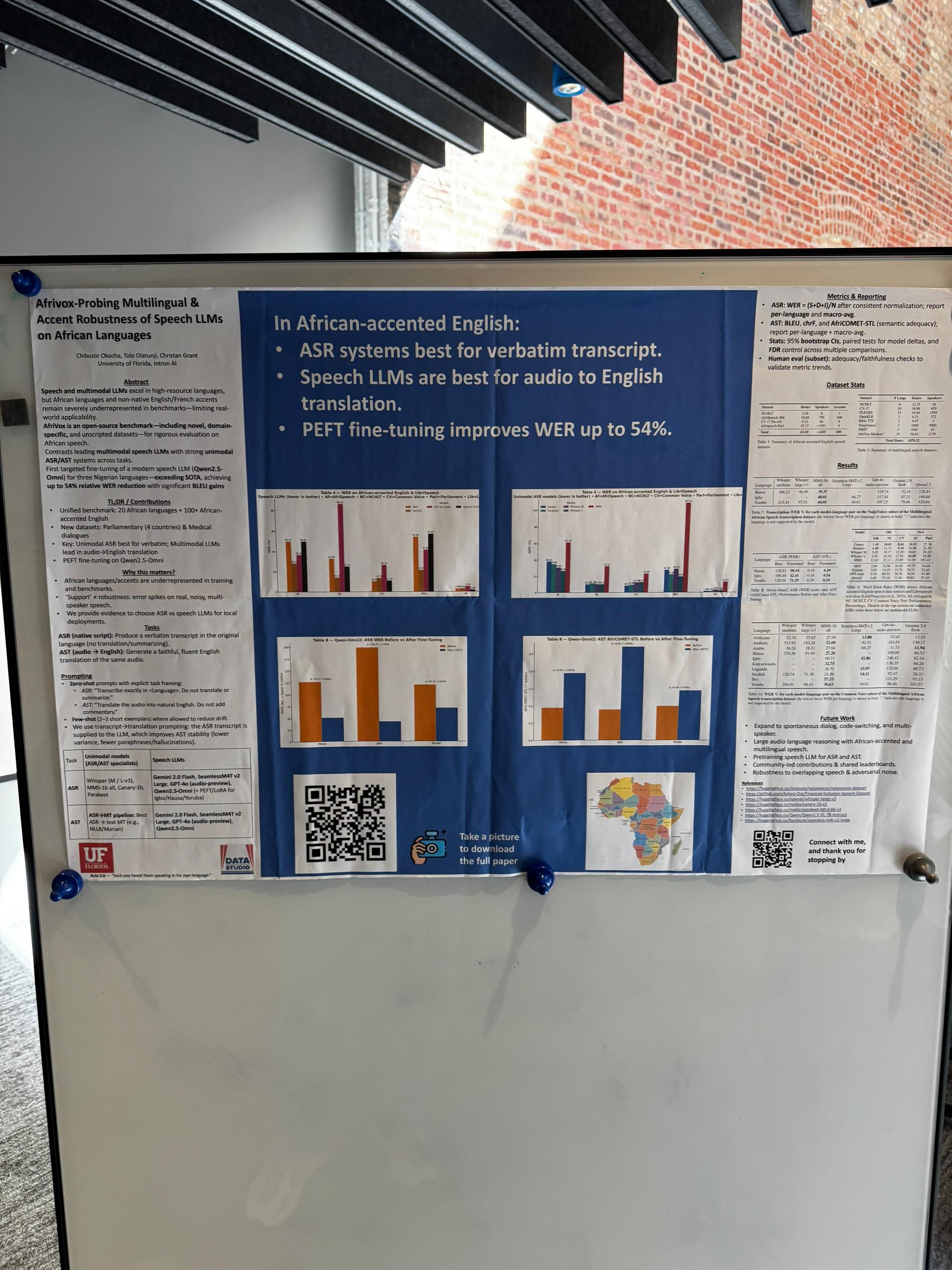 My AfriVox poster showcasing the framework for fairer evaluation of African-accented speech in audio-language models.
My AfriVox poster showcasing the framework for fairer evaluation of African-accented speech in audio-language models.
Next Steps: I plan to (a) pretrain an accent- and multilingual-aware ALM or (b) fully fine-tune strong bases (e.g., Whisper-style encoders + ALM heads like Qwen2-Audio/SALMONN/GAMA/Audio-Flamingo) and run ablation studies by accent, language family, and noise. I’ll also expand reasoning and understanding tasks—temporal/audio event reasoning, multi-turn spoken instructions, and cross-modal grounding—to stress models beyond transcription, prioritizing reliability, safety, and equity in low-resource, accented settings. seeds, and versions) for easy reruns.
Takeaways I’m Bringing Back to UF Data Studio
I received encouraging feedback on AfriVox, particularly on the need to refine its sampling strategy by ensuring a balanced pairing of accents and tasks. Many attendees appreciated the focus on accent fairness, and the conversations sparked new directions I’m excited to pursue. I plan to extend the current work beyond evaluation and into speech generation for accented voices, especially thinking about how audio-language models can be tuned to not only recognize but also generate African-accented speech with authenticity and style control.
This connects directly with ideas I picked up from talks on speech generation and stylistic control—showing that fairness in speech AI isn’t just about measuring errors, but also about creating models that can represent diverse voices in expressive and equitable ways.
Trip Notes
- Chicago in September = perfect workshop weather ☀️
- Hyde Park coffee chats turned into mini-brainstorms on data cards and accent coverage.
- Poster hour was packed—lots of interest in how to make fairness measurements easy to adopt.
Photos
 Presenting the AfriVox poster during the TTIC workshop - great discussions about accent fairness in speech AI.
Presenting the AfriVox poster during the TTIC workshop - great discussions about accent fairness in speech AI.
Acknowledgments
Huge thanks to the TTIC organizers and all the speakers/panelists for an inspiring program. Grateful to UF Data Studio and my mentors for the guidance that shaped AfriVox. also thanks to travel support/sponsors that helped make this trip possible.
 Chicago skyline from the workshop venue - the perfect setting for advancing speech AI research.
Chicago skyline from the workshop venue - the perfect setting for advancing speech AI research.
If you’re interested in collaborating on accent-aware evaluation, generation, or trying the AfriVox starter kit, reach out—I’m happy to share scripts and notes.