The Automatic Speech Recognition Inclusivity Dilemma

Automatic Speech Recognition (ASR) is a technology that many of us use every day. Applications such as virtual assistants (e.g., Apple's Siri and Google's Virtual Assistant), live captioning, and audio transcription all use the technology of ASR in different capacities. While this technology has positively affected the world by increasing the efficiency of audio transcription and adding additional mediums of accessibility, those who speak with dialects, accents, patois, and creole foreign to an ASR model are often misunderstood. However, after years of technological progress, this problem still widely pervades the ASR models used today. I've observed this phenomenon play out --- often hilariously --- while growing up in a Caribbean household with parents who speak Jamaican patois. In the following sections we will explore how ASR works, why there is a bias towards the accents it is able to accurately transcribe, and what we can do to remedy this problem.
Modern ASR Methods?
Before we can train an ASR model on speech, audio must be extracted and preprocessed into the most optimal format for training.
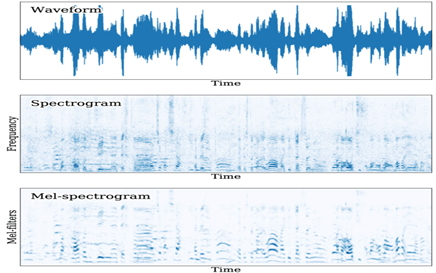 Figure 1 - Visualizing a 10-second speech segment from Google AudioSet through waveform, spectrogram, and mel-spectrogram The mel-spectrogram, tuned to the mel-frequency scale, enhances lower-frequency details compared to the spectrogram. (source)
Figure 1 - Visualizing a 10-second speech segment from Google AudioSet through waveform, spectrogram, and mel-spectrogram The mel-spectrogram, tuned to the mel-frequency scale, enhances lower-frequency details compared to the spectrogram. (source)
We first use the raw waveform of the audio and transform it into a spectrogram using a discrete Fourier transformation, which generates the frequency and magnitude of the audio.
We can visualize spectrums by plotting the magnitude against frequency (as shown above).
Because humans hear on a logarithmic scale, we perform a log transformation (pictured below) on the raw frequency of the audio, creating the "Log Mel Spectrogram" (a Mel is a unit of pitch).
After the ASR data is transformed into the proper format we can choose one of the two common ASR algorithms: the Attention-based encoder-decoder (AED) model and the Connectionist Temporal Classification (CTC) model.
Attention-based encoder-decoder (AED) model
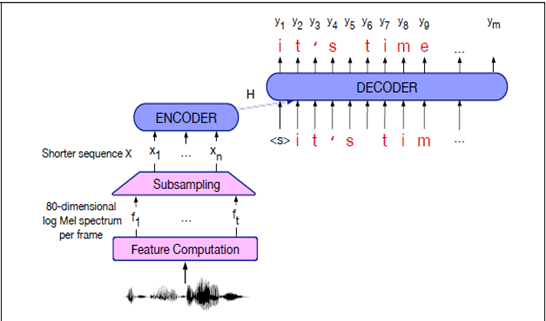 Figure 2 - AED model architecture.
Figure 2 - AED model architecture.
The AED Model consists of three major components.
Encoder. The encoder's job is to process the audio input (speech) and convert it into a more compact representation, often called the "context" or "hidden state." It does this by analyzing small chunks or frames of the audio sequentially. Each frame of audio is converted into a meaningful numerical representation .
Attention Mechanism. The attention mechanism comes into play during the decoding phase. The encoder produces the context, which is a summary of the input speech. The decoder's task is to take this context and generate the corresponding text (transcription). The attention mechanism helps the decoder focus on relevant parts of the input context at each step of generating the output, enabling the model to weigh the importance of different parts of the input speech as it generates the corresponding text. During training, the backpropagation process aids the attention mechanism in learning to attend to specific parts of the input context that are more relevant for generating the corresponding output text.
Decoder. The decoder is fed a start of sequence token <sos> by the encoder to know where to start decoding. The decoder then uses the attention mechanism to produce the text output one step at a time. At each step, the decoder "attends" to specific parts of the context (using the attention mechanism) and generates the most likely text output for that step. It continues this process until it reaches an end of sequence token <eos> and the entire text transcription is generated.
| Pro | Attention encoder-decoder functions produce the most accurate transcriptions of speech compared to other algorithms used for ASR generation. |
| Con | Algorithms that use attention need to first compute the hidden state sequence over the entire input in order to provide the attention distribution context before the decoder can start decoding. This means that the model can only transcribe audio that has been pre-recorded. |
Connectionist Temporal Classification (CTC) model
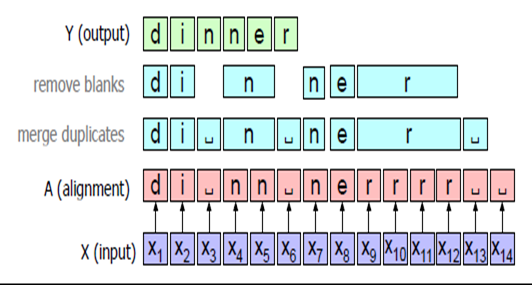
 Figure 3 - CTC model architecture.
Figure 3 - CTC model architecture.
The frequency of frames in Mel spectrograms is evaluated by analyzing the distribution of acoustic energy across different frequency bands within each frame. Each frame is then assigned a corresponding letter or character based on the phoneme that the model determines aligns best with the frequency characteristics present in the provided speech.
Using the CTC algorithm, a process called alignment that merges duplicates adjacent characters. This step is important to handle situations where the model might predict the same phoneme multiple times consecutively.
Once the duplicates are merged, the algorithm removes any remaining blanks.
The remaining characters and letters are joined to create a word (output). This algorithm continues across the full source.
| Pro | Great for auto-generation or transcription of words while a speaker is still speaking (live captioning). |
| Con | Less accurate than AED due to its use of time intervals between word phonemes to piece letters together (alignment variation based on how one pronounces a word). |
The problem
The problem of ASR not being able to accurately transcribe English speech that contains a variety of linguistic differences, including vernacular, dialect, and accent, can be largely attributed to a bias in the data that a specific ASR model has been trained. Take, for example, OpenAI's ASR model Whisper, which has been trained on 680,000 hours of multilingual and multitask-supervised data collected from the web. The robustness of this model suggests that it is great at transcribing all types of speech, Whisper has shown problems in transcribing low-resource languages as well as niche variations of English. This is because Whisper was trained on data where speakers mostly spoke standard American English, while less commonly used English variations were left out to cater to the generality of the model. Another possible reason for the lack of accurate niche speech variation transcription in ASR models could be an economic decision made by companies. A large portion of the publicly available corpora of human-created transcripts only consists of transcripts of standard American English. For companies to train their models on less commonly used variations of English, they'd have to hire people who can understand or speak that version of English to make transcripts of recorded audio of people using that variation of English. The process detailed above can not only be costly but also time intensive. With reports suggesting that "The variety of English with the largest number of native speakers is American English, with 225 million native speakers" (Grammarist), it's understandable why most companies forego the extra costs in training models on lesser used speech varieties. However, there should be ASR models that offer accurate speech-to-text transcription to demographics that speak unorthodox variations of English.
Possible solutions
OpenAI has acknowledged the discrepancies of Whisper being able to accurately transcribe versions of English speech that deviate from standard American English on their website, stating, "Because Whisper was trained on a large and diverse dataset and was not fine-tuned to any specific one, it does not beat models that specialize in LibriSpeech performance, a famously competitive benchmark in speech recognition", and a very important word used above is "fine-tuned". Fine-tuning is the process of taking a model that is already great at doing a task and training it on new data for a new task. Because OpenAI has open sourced its Whisper model, developers can take advantage of Whisper's current capability of transcribing and translating languages and fine-tune it to perform transcription and translation for a certain speech variation with greater accuracy than what the base or generalized model can do. By creating fine-tuned models, companies that utilize ASR capabilities in their products can now implement a more equitable and inclusive use of the technology for a larger demographic of people.
Citations
[1] "Introducing Whisper." Introducing Whisper, https://openai.com/research/whisper.
[2] Jones, Joshua. "Im Confused Im Not Sure I Understand Gif - Im Confused Im Not Sure I Understand I Am Not Sure I Understand - Discover & Share Gifs." Tenor, 28 Apr. 2021, https://tenor.com/en-CA/view/im-confused-im-not-sure-i-understand-i-am-not-sure-i-understand-siri-siri-im-not-sure-i-understand-gif-21354974.
[3] Jurafsky, Dan, and Martin, James H. "Speech and Language Processing." Stanford University, 7 Jan. 2023,https://web.stanford.edu/~jurafsky/slp3/.
[4] "Varieties of English." GRAMMARIST, 27 Sept. 2022, https://grammarist.com/varieties-of-english/.