Language Documentation and Revitalization

Written by: Oluwasijibomi “S.J” Ajisegiri
Introduction
As part of my research ideas, I am currently looking into how language revitalization and documentation can be made accessible for interested and willing parties to learn languages using Technology.
This blog post will discuss one of the papers I have read in this field: Oliver Adams et al., 2021. User-friendly Automatic Transcription of Low-resource Languages: Plugging ESPnet into Elpis. In Proceedings of the 4th Workshop on the Use of Computational Methods in the Study of Endangered Languages Volume 1 (Papers), pages 51–62, Online. Association for Computational Linguistics.
By researching more on this topic, I hope that I will be able to build something for linguists and language revitalization programmed to use in teaching languages in the nearest future.
This semester is the start of exploring the field I would like to base my research on, and although that brings some uncertainty, I have started getting some little clear-cut ideas on what to do. A lot of the research done and papers written in computer science is a continuously fast-paced situation that makes it hard to keep up with new ideas and improvements on old ideas.
The subject of this blog post is clear: User-friendly Automatic Transcription of Low-resource Languages: Plugging ESPnet into Elpis.
Speech Transcription
First off, we start by defining Speech Transcription; this is the art of transcribing spoken audio in a video or video segment into text and returning blocks of text for each portion of the transcribed audio. Transcription of speech is an integral part of language documentation, yet speech recognition technology has not been widely harnessed to aid linguists.
Plugging ESPnet into Elpis.
ESPnet is an end-to-end neural network-based speech recognition toolkit. Also, Elpis is a toolkit that provides a user-friendly front-end/interface to the Kaldi speech recognition system—developed using PyTorch for easy modification and active development.
Goal: One goal of the integration is to create a default ESPnet recipe for Elpis to use that performs well across various languages and with the small amount and type of data typically available in a language documentation context.
Architecture: This is the Hybrid CTC-attention model with a 3-layer BiLSTM encoder and a single decoder. This is developed using Pytorch because it makes it easy to modify training recipes, including scripts and configuration files. Additionally, the CUDA training uses a docker image. Some related work includes automatic phonetic/phonemic transcription in language documentation.
Dataset
The data set comprises about 30 hours of transcribed recordings of narratives, time-aligned at the level of the sentence (Macaire, 2020), which is a massive amount in a language documentation context.

Results
The graph below shows how the phoneme error rate decreases as the training data increase up to 170 minutes. There seems to be some belief that the performance stagnates the training time is increased beyond 170 minutes. Hence, more experiment is still being conducted.
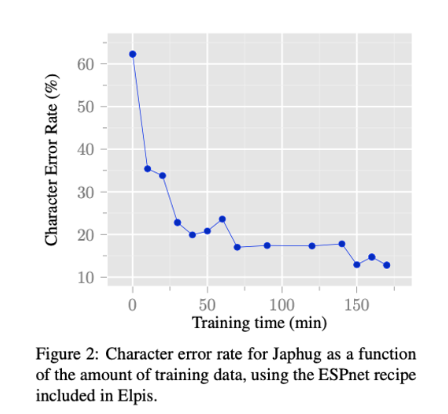
The model used was trained for 20 epochs for each amount of training data, with the smaller sets as a subset of all larger sets. The graph below shows the training profile for a given training run using 170 minutes of data.

Challenges
This system's challenges include being too complex, which means that new technologies that seem inaccessible to language workers can be game-changers in linguistics. Additionally, the researchers fear that they will not Deliver on the Promise. Currently feels out of reach even though progress is being made on both LDR and computer Science.
Improvements
Pre-training & Transfer Learning: In scenarios where data in the target domain or language is limited, leveraging models trained on several speakers in different languages often can result in a better performance. The language documentation scenario, where minimal annotated data is a scenario that we argue stands the most to gain from such pre-training (both supervised and self-supervised out-of-domain), followed by model adaptation to limited target language data.
Web-AAS: Training models require a lot of computing power. Elpis now supports high-speed parallel processing when the user's operating system has compatible GPUs. Providing language technologies using web services appears to be a successful method of making tools widely available, with examples including the WebMAUS forced-alignment tool.
Conclusion
I believe this is an excellent start to integrating ESPnet (an end-to-end neural network speech recognition system) into Elpis (a user-friendly speech recognition interface). Furthermore, the addition of a CUDA-supported Elpis Dockerfile proves to improve the overall experience of Elpis use.
Reference
[1]: Lambourne, Nicholas, et al. "User-friendly automatic transcription of low-resource languages: Plugging ESPnet into Elpis." (2021).